




従来の大規模言語モデルの制約だった「入力量の限界」を取り払った「RWKV」は一体どんな言語モデルなのか?

ChatGPTやBardなど、2023年7月時点で商用利用されている大規模言語モデルはほとんど全てがトランスフォーマーというアーキテクチャを利用したモデルですが、トランスフォーマー型のモデルは入力の長さの2乗に比例して計算量が増加するため、入力サイズが制限されてしまう問題があります。そうした問題に応えて、大きいデータへの対応や推論時のメモリ使用量の削減を達成しつつトランスフォーマー型に匹敵する性能を出せるアーキテクチャ「RWKV」について、著者の一人がブログで解説しています。
The RWKV language model: An RNN with the advantages of a transformer | The Good Minima
https://johanwind.github.io/2023/03/23/rwkv_overview.html
How the RWKV language model works | The Good Minima
https://johanwind.github.io/2023/03/23/rwkv_details.html
RWKVはRNN(回帰型ニューラルネットワーク)がベースとなっています。RNNは入力されたトークンを1つずつ順番に処理して状態ベクトルを更新する仕組みです。

テキストをトークン化して順次読み込ませることで単一の状態ベクトルにしたり、最終結果をもとに次のトークンを予測してテキスト生成タスクをこなしたりすることが可能です。テキストがトークン化される様子については下記の記事がわかりやすいです。
ChatGPTなどのチャットAIがどんな風に文章をトークンとして認識しているのかが一目で分かる「Tokenizer」 - GIGAZINE

RNNは「入力を1つずつ順番に処理する」という性質を持つため、GPUなどを利用して大規模に並列化するのが困難でした。そこで、入力を逐次処理するRNNの代わりに「アテンション」という仕組みを利用して全ての入力トークンを同時に処理する「トランスフォーマー」が生み出されました。計算を大規模に並列化することが可能になったため、大きなモデルとデータセットでも高速にトレーニングでき、ChatGPTなど多数の優れた大規模言語モデルを生み出しました。
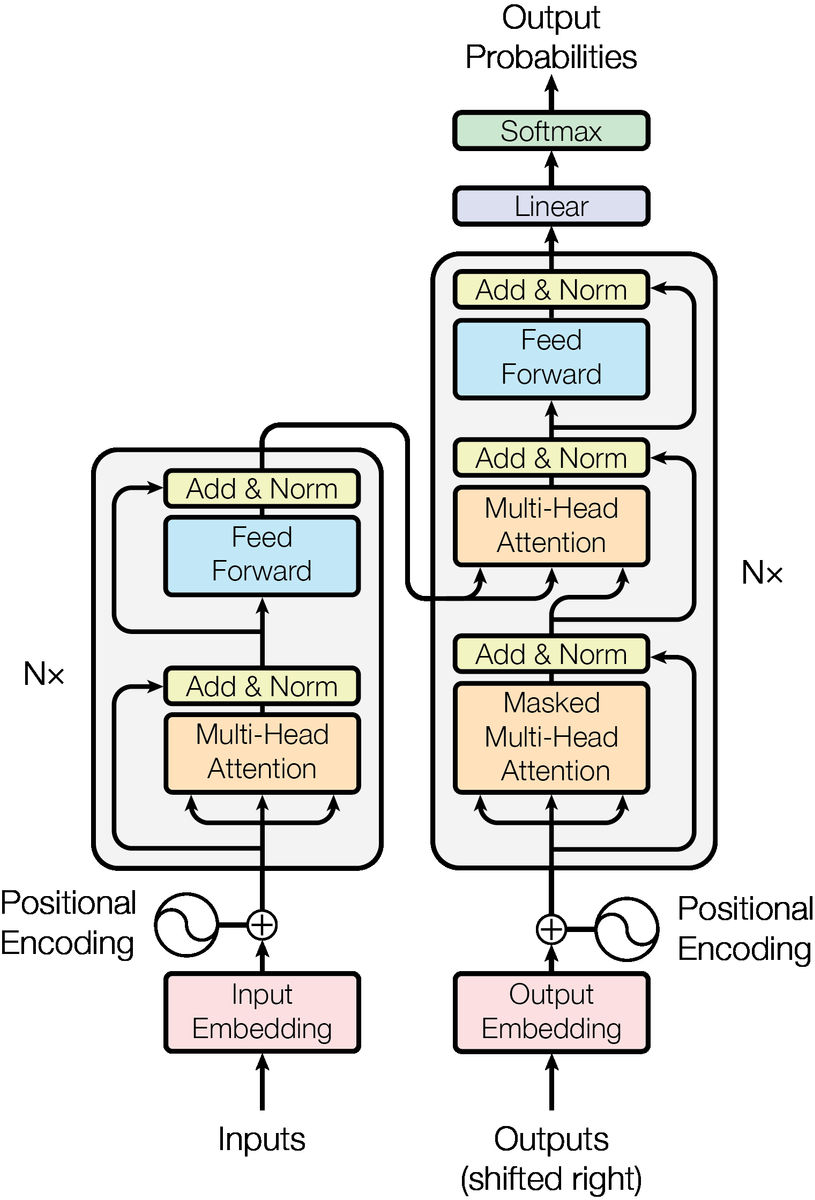
しかし、アテンションの計算においては入力トークン間の全てのペアについて計算する必要があるため、処理に必要な時間が入力トークンの量の2乗に比例してしまうほか、テキストを生成する時には全トークンのアテンションベクトルを利用するのでメモリを大量に必要とするなど、入力トークンの長さに関して制限が存在しています。一方、RNNの場合は計算量が入力トークンの量の1乗に比例するため、かなり長い文章を「読む」ことが可能です。
RWKVはトランスフォーマー同様に入力トークンを同時に処理することで並列化を可能にしつつ、RNNのように長大な入力を行っても高速に計算することも可能という「両者のいいとこ取り」をしたアーキテクチャとのこと。下図の通りの構造を持っており、「Time Mixing」ブロックと「Channel Mixing」ブロックに分かれているのが特徴です。このアーキテクチャの「RWKV」という名前は、過去の情報の受容度を表すRベクトルや時間係数を表すWベクトル、そしてアテンションで使用される「Key」「Value」と同様のベクトルが利用されているところから、それぞれの頭文字を取って名付けられています。
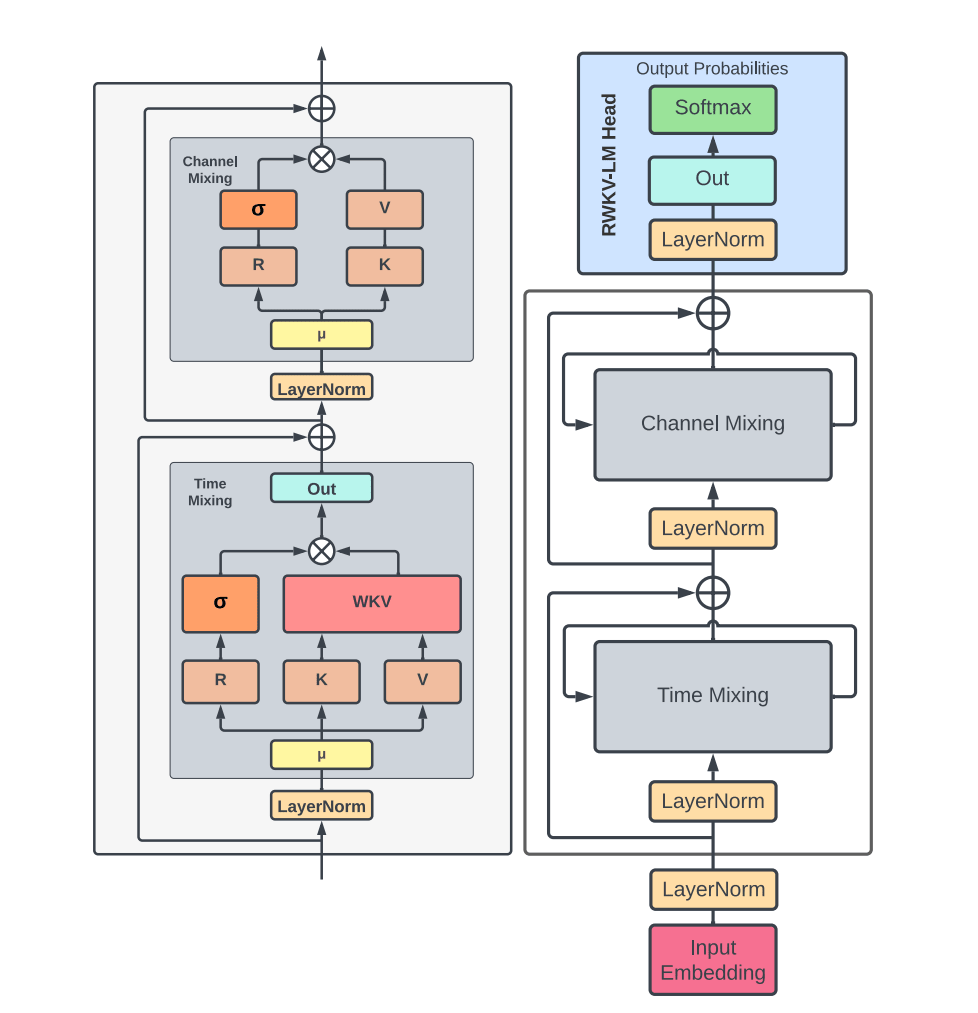
RWKVは構造の中でレイヤーを分けることで、RNNの前のノードの計算が終わる前に次のノードの計算を始めることが可能です。下図の通り、最初に左端列の「My→name」のTime Mixingブロックの計算をした段階で、次の「name→is」列のTime Mixingブロックの計算を始めることができます。こうしてRNNであるにも関わらず大規模な並列化を可能にしているというわけです。なお、こうして並列化を行うのは学習時のみで、推論時には逐次計算することでメモリの消費量を大幅に削減できるとのこと。

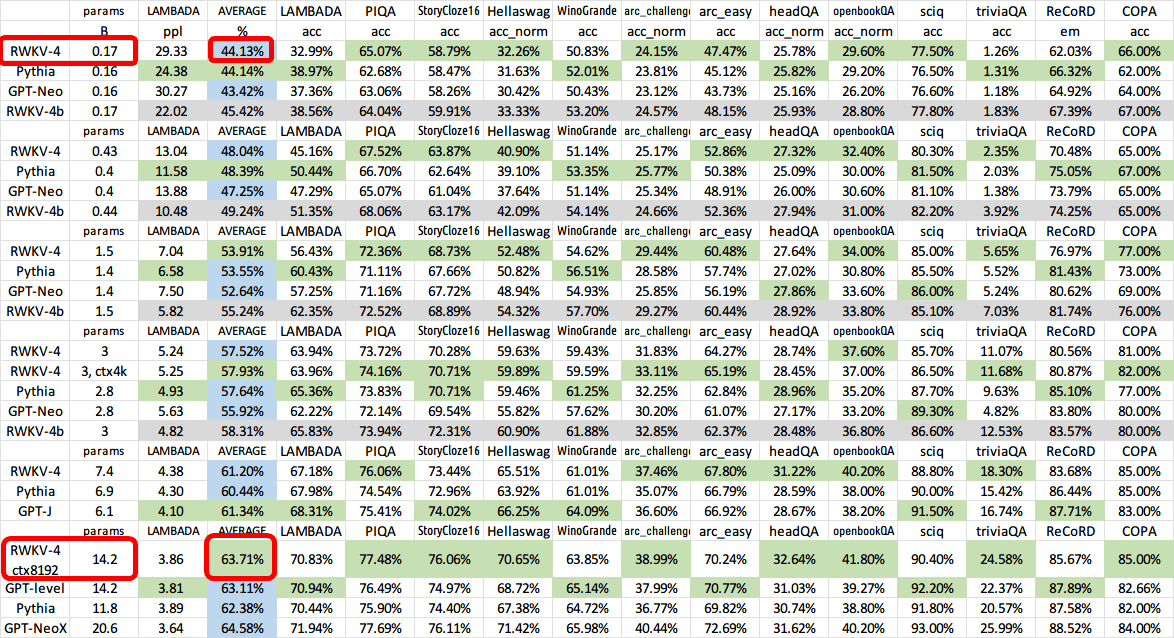
LAMBADAやPIQAなどを用いた性能評価では、RWKVは小さいパラメーター数から大きいパラメーター数へと増やしてもトランスフォーマー型のモデルに匹敵する性能を出せたとのこと。
RWKVの実装については、RWKV論文の著者の一人であるジョハン・ウィンドさんが約100行のRWKVの最小実装を解説付きで公開しているので気になった人は確認してみてください。
・関連記事
ChatGPTなどの大規模言語モデルはどんな理論で成立したのか?重要論文24個まとめ - GIGAZINE
大規模言語モデルの開発者が知っておくと役立つさまざまな数字 - GIGAZINE
独自のデータセットでGPTのような大規模言語モデルを簡単にファインチューニングできるライブラリ「Lit-Parrot」をGoogle Cloud Platformで使ってみた - GIGAZINE
大規模言語モデルの出力スピードを最大24倍に高めるライブラリ「vLLM」が登場、メモリ効率を高める新たな仕組み「PagedAttention」とは? - GIGAZINE
GPUメモリが小さくてもパラメーター数が大きい言語モデルをトレーニング可能になる手法「QLoRA」が登場、一体どんな手法なのか? - GIGAZINE
・関連コンテンツ








in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article What kind of language model is `` RWKV &….