'ZAYA1-8B,' a large-scale AI approaching the capabilities of large-scale AIs with approximately 700 million parameters, has been released. Trained in an AMD environment, it achieves performance comparable to large-scale models in mathematical and code-based inference.

American AI startup Zyphra has released 'ZAYA1-8B,' a compact inference language model trained on AMD's GPU infrastructure. The weights are publicly available, and commercial use is permitted.
Zyphra
ZAYA1-8B is a Mixture of Experts (MoE) model that has approximately 8 billion parameters in total, but limits the number of effective parameters mainly used during inference to about 700 million. By utilizing the MoE method, which calls only a portion of the experts that match the input from multiple expert networks, ZAYA1-8B achieves high inference performance while keeping computational complexity low. Zyphra explains that ZAYA1-8B performs close to that of large-scale models in mathematical, coding, and complex inference tasks.
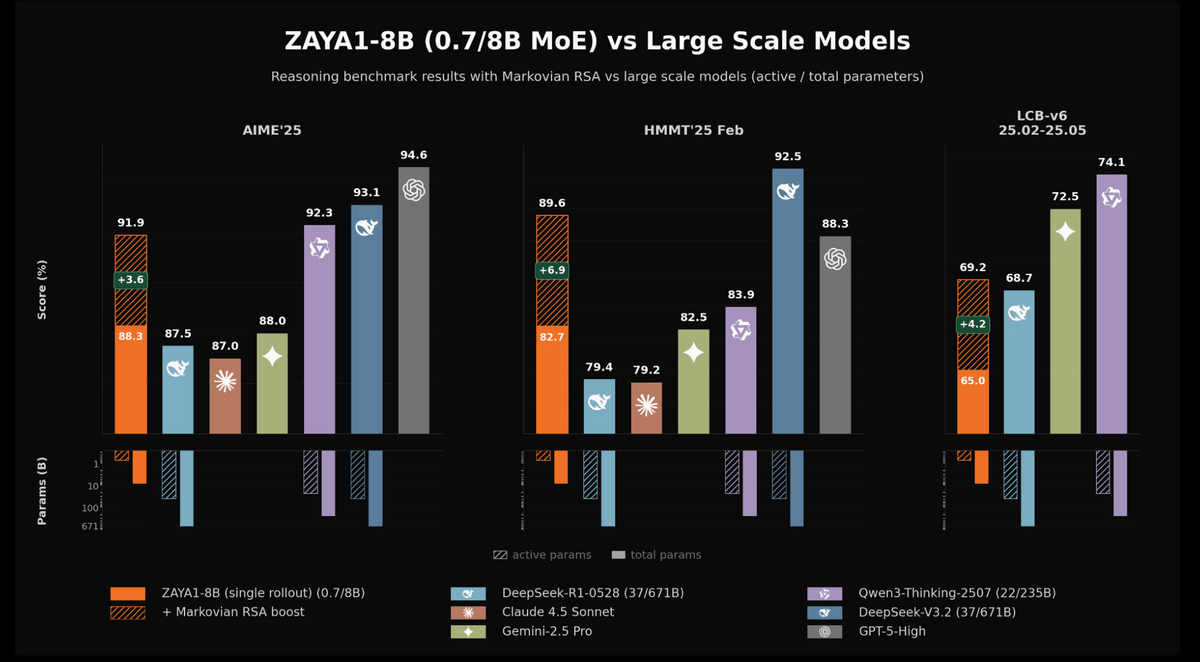
The following graph compares ZAYA1-8B with various large-scale models using inference benchmarks for AIME'25, HMMT'25 Feb, and LCB-v6 25.02-25.05. ZAYA1-8B achieved 88.3% in AIME'25, 82.7% in HMMT'25 Feb, and 65.0% in LCB-v6. By adding an additional inference computation called 'Markov-type RSA,' these scores improved to 91.9%, 89.6%, and 69.2%, respectively. The lower section shows the number of effective parameters and total parameters for each model, demonstrating that ZAYA1-8B, despite being a small MoE model with approximately 700 million effective parameters and 8 billion total parameters, achieves scores close to those of large-scale models.
Zyphra particularly emphasizes 'intelligence density per effective parameter.' While models with a larger number of parameters generally tend to perform better, ZAYA1-8B has kept its effective parameters below 1 billion, yet it has demonstrated competitive scores in mathematical benchmarks such as AIME and HMMT, coding benchmarks such as LCB (LiveCodeBench), knowledge and reasoning benchmarks such as GPQA-Diamond, and instruction-following benchmarks such as IFEval and IFBench. Zyphra explains that it outperformed much larger weighted public models like Mistral-Small-4-119B in some mathematical and coding evaluations.
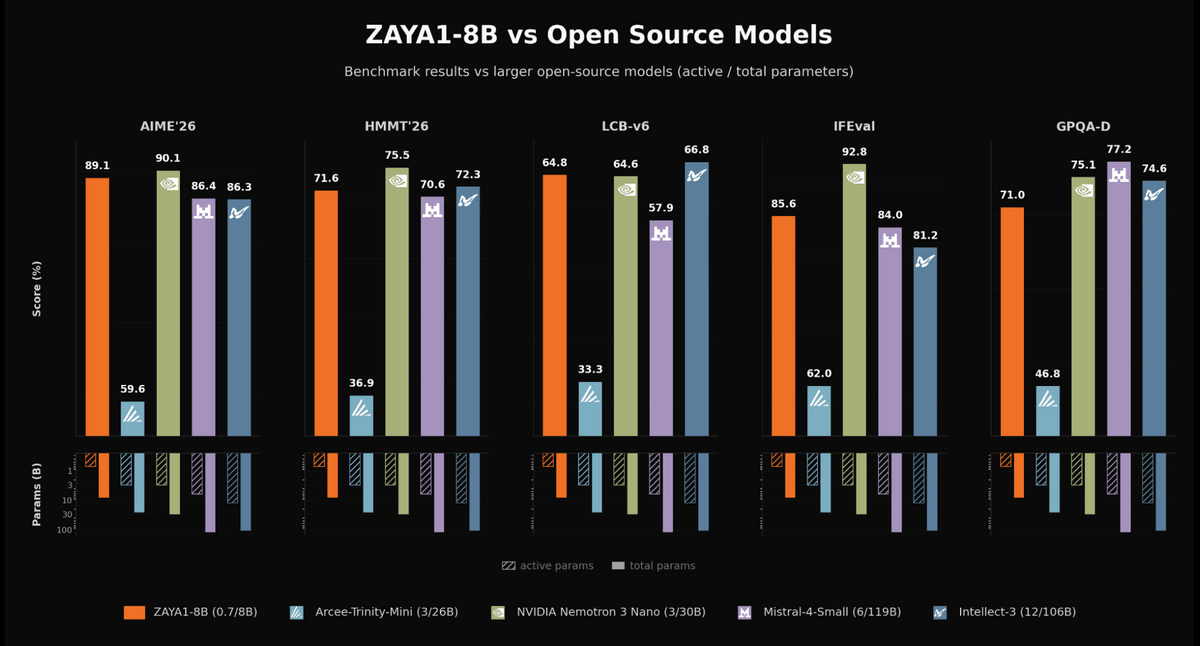
The following graph compares ZAYA1-8B with large open-source models using five benchmarks: AIME'26, HMMT'26, LCB-v6, IFEval, and GPQA-D. ZAYA1-8B achieved 89.1% on AIME'26, 71.6% on HMMT'26, 64.8% on LCB-v6, 85.6% on IFEval, and 71.0% on GPQA-D. The comparison targets included Arcee-Trinity-Mini, NVIDIA Nemotron 3 Nano, Mistral-4-Small, and Intellect-3. Despite its small configuration of approximately 700 million effective parameters and 8 billion total parameters, ZAYA1-8B demonstrated competitive results in multiple evaluations, including those testing mathematics, coding, instruction following, and expertise.
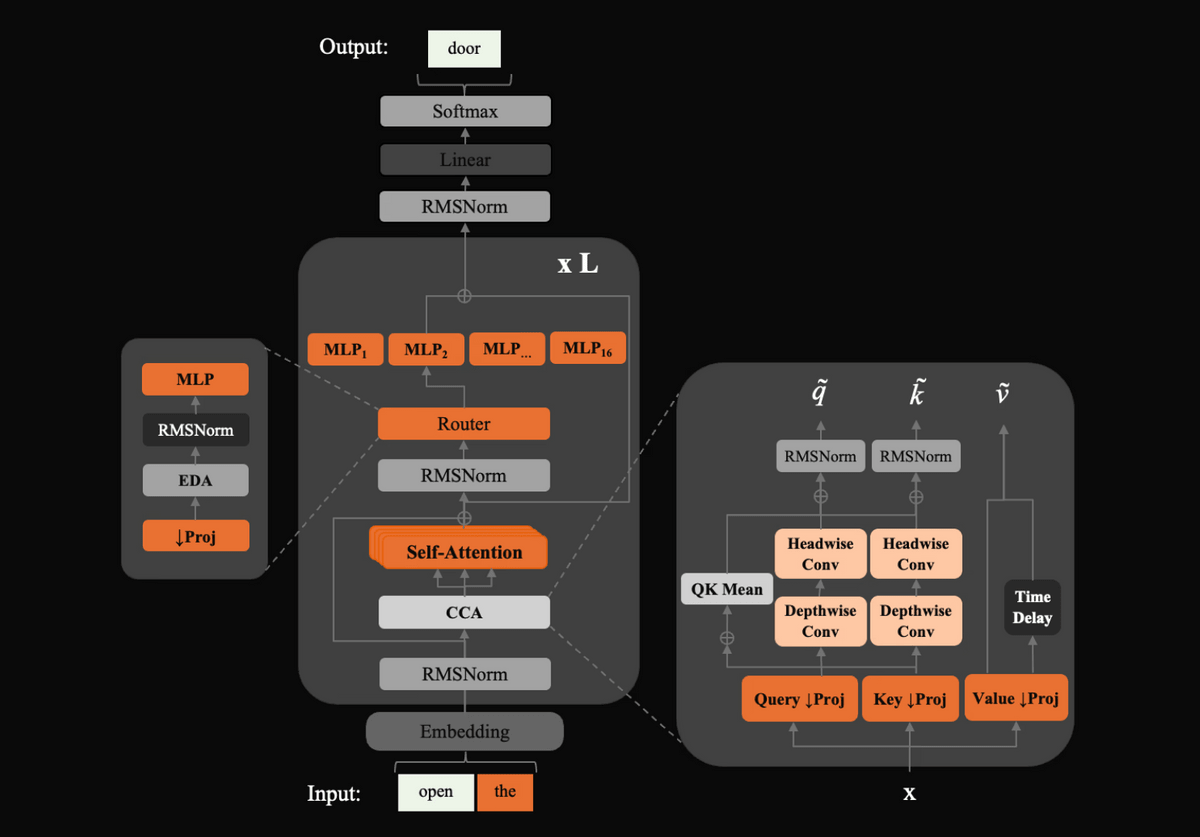
The ZAYA1-8B design incorporates three mechanisms for efficiency. The first is 'Compressed Convolutional Attention (CCA)' to optimize the attention mechanism, which tends to be computationally intensive in Transformers. The second is the adoption of an MLP-based router for the router, which is the component that selects the expert network to call in MoE. According to Zyphra, the MLP-based router enables more stable expert selection than a linear router. The third is learnable residual scaling, which controls the size of the internal representation, as stacking residual connections to deep layers tends to increase the size.
The following diagram shows the model structure of ZAYA1-8B. After the input token passes through the Embedding layer, it is processed in a block containing RMSNorm, CCA, Self-Attention, MoE router, and multiple MLP experts, finally generating the output token. On the right, the Query, Key, Value processing and convolution processes within the CCA are shown in detail, revealing a design that incorporates an efficient attention mechanism.
According to Zyphra, ZAYA1-8B underwent pre-training, intermediate training, and supervised fine-tuning in an AMD Instinct MI300-based environment. The training reportedly utilized 1024 AMD Instinct MI300X nodes, an AMD Pensando Pollara interconnect, and a custom training cluster built with IBM. While NVIDIA GPUs tend to be the focus of discussion regarding large-scale AI model training environments, ZAYA1-8B is noteworthy as an example demonstrating that competitive inference models can be created using the AMD stack.
ZAYA1-8B's performance isn't solely due to pre-training. Zyphra explains that after supervised fine-tuning, they performed inference warm-up, large-scale reinforcement learning, reinforcement learning specifically for mathematics and coding, and further improved chat quality and behavior using reinforcement learning with human feedback (RLHF) and reinforcement learning with AI feedback (RLAIF). ZAYA1-8B showed improvements not only in easily verifiable areas like mathematics and coding, but also in following instructions and creative writing.
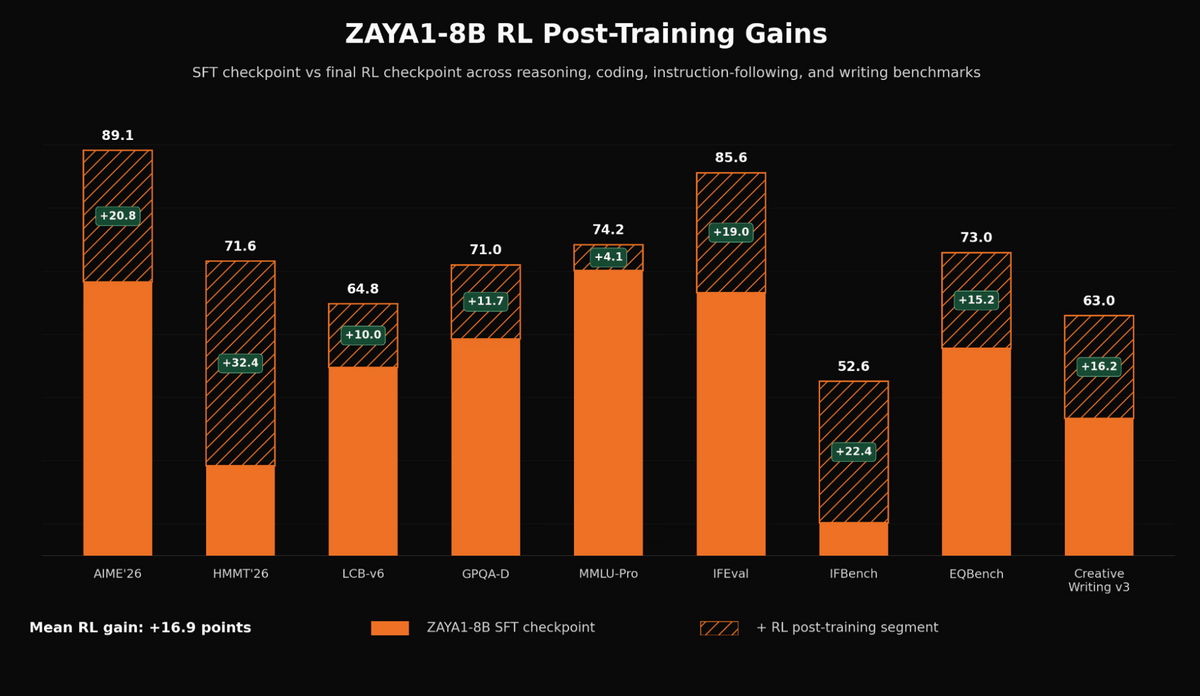
The graph below shows the performance improvement achieved through reinforcement learning-based post-training in ZAYA1-8B. The orange area represents the score after supervised fine-tuning, and the shaded area represents the additional improvement due to reinforcement learning. Significant improvements can be seen in AIME'26, HMMT'26, IFEval, and IFBench. On average, the score improvement is 16.9 points.
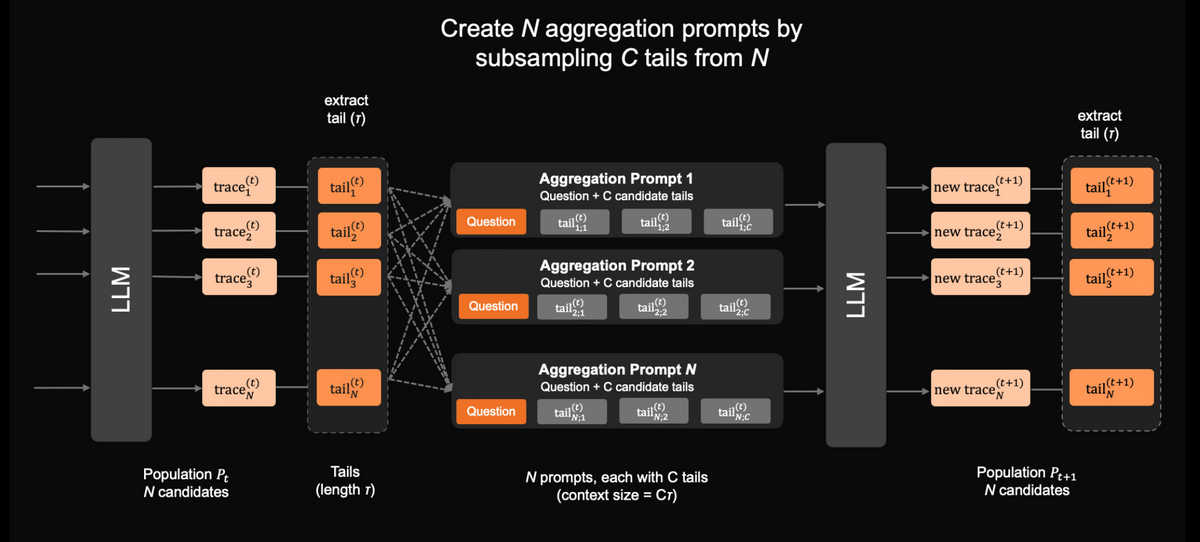
Another highlight of ZAYA1-8B is its 'Markov RSA.' Markov RSA is a type of mechanism called inference-time augmentation, which generates multiple candidates during the answer-making stage instead of increasing the model's weights, and then integrates these candidates to improve accuracy. In ZAYA1-8B's Markov RSA, multiple inference processes are generated in parallel, only the end of each inference process is extracted, and an aggregated prompt, which is a combination of these end fragments, is used for the next inference. Because long inference processes are not passed entirely to the next stage, the design allows for longer thinking while suppressing the increase in context length.
The following diagram illustrates the procedure for integrating multiple inference candidates using a Markov-type RSA. First, the LLM generates N inference processes and extracts the end portion from each process. Next, C elements are sampled from each of the N end portions to create N aggregate prompts, and each prompt is input back into the LLM to generate a new inference process. Because the context size of the aggregate prompts is limited, the system does not retain the entirety of past inferences but rather inherits only the key points of the candidates, thereby gradually improving the quality of the inference.
Zyphra explains that ZAYA1-8B, which uses a Markov RSA model, outperformed Claude 4.5 Sonnet and GPT-5-High at HMMT'25. However, the performance using Markov RSA is the result of additional inference computations, not just the usual single inference. The strength of ZAYA1-8B seems to lie not in 'always replacing large frontier models,' but rather in 'giving small models additional inference time to achieve significant improvements in easily verifiable problems such as mathematics and coding.'
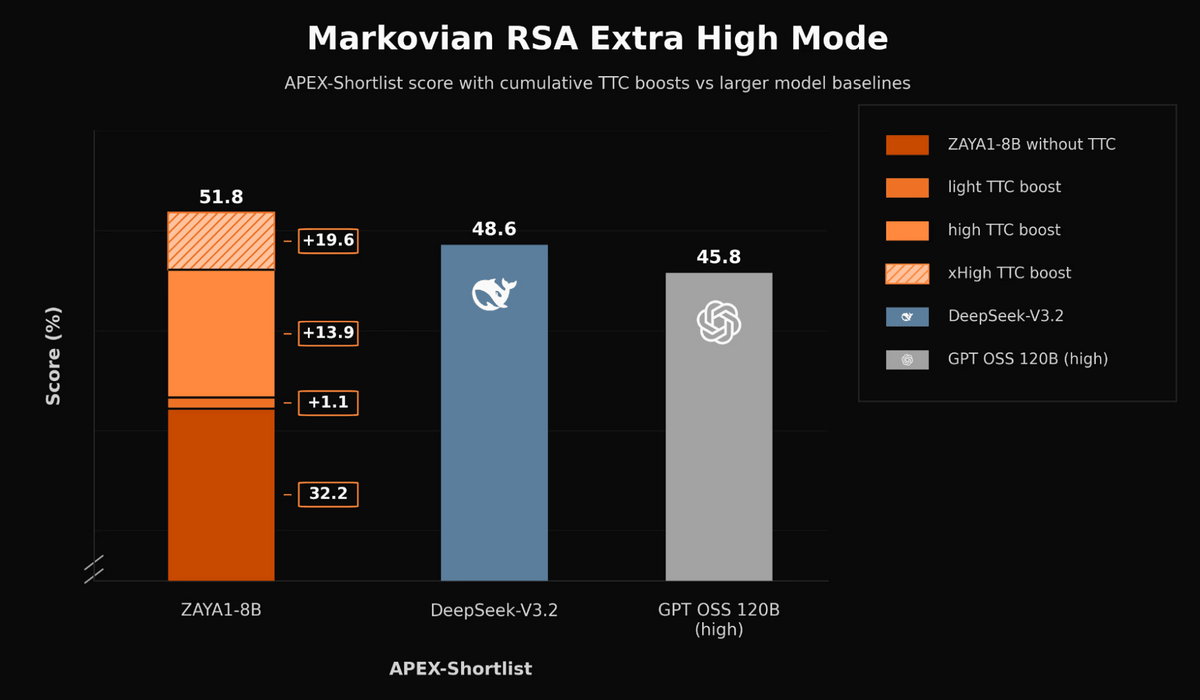
The figure below is a comparison graph showing the effect of additional computation during inference using Extra High Mode for Markov RSA. ZAYA1-8B achieves 32.2% in APEX-Shortlist without additional computation during inference, but by gradually increasing the additional computation, it eventually reaches 51.8%, surpassing DeepSeek-V3.2's 48.6% and GPT OSS 120B's 45.8%.
ZAYA1-8B is available from Zyphra Cloud's serverless endpoint, and its model weights are also publicly available on Hugging Face . It is licensed under Apache 2.0 and can be used for both research and commercial purposes.
Related Posts:







in AI, Posted by log1d_ts