Anthropic has announced a 'natural language autoencoder' that translates the thoughts of AI models into language.

When AI models like Claude process words internally, they treat them as 'activation values,' which are long sequences of numbers that encode thoughts and are difficult to decipher. For many years, Anthropic has been developing various tools to understand activation values, and has now announced 'Natural Language Autoencoders (NLAs)' that translate them into human-readable natural language.
Natural Language Autoencoders\Anthropic
The essential idea behind NLAs is to 'train Claude to explain its own activation values.' However, since we don't know what kind of thoughts the activation values encode, we can't verify whether the explanation is accurate. Therefore, we trained a second instance of Claude to perform the reverse process of reconstructing the original activation values from a textual explanation. If the reconstruction was accurate, we determined that the explanation was appropriate. After that, we trained the original Claude using standard learning to generate a better explanation.
Anthropic is already using NLAs to understand 'what Claude is thinking' and to improve safety and reliability.
For example, in a case where Claude Mythos Preview cheated on a training task, NLAs analysis confirmed that Claude was internally exploring ways to evade detection.
Furthermore, in an early version of Claude Opus 4.6, there was an incident where it sometimes gave incomprehensible answers in other languages to questions in English. Thanks to NLAs, it was discovered that the cause was in the training data.
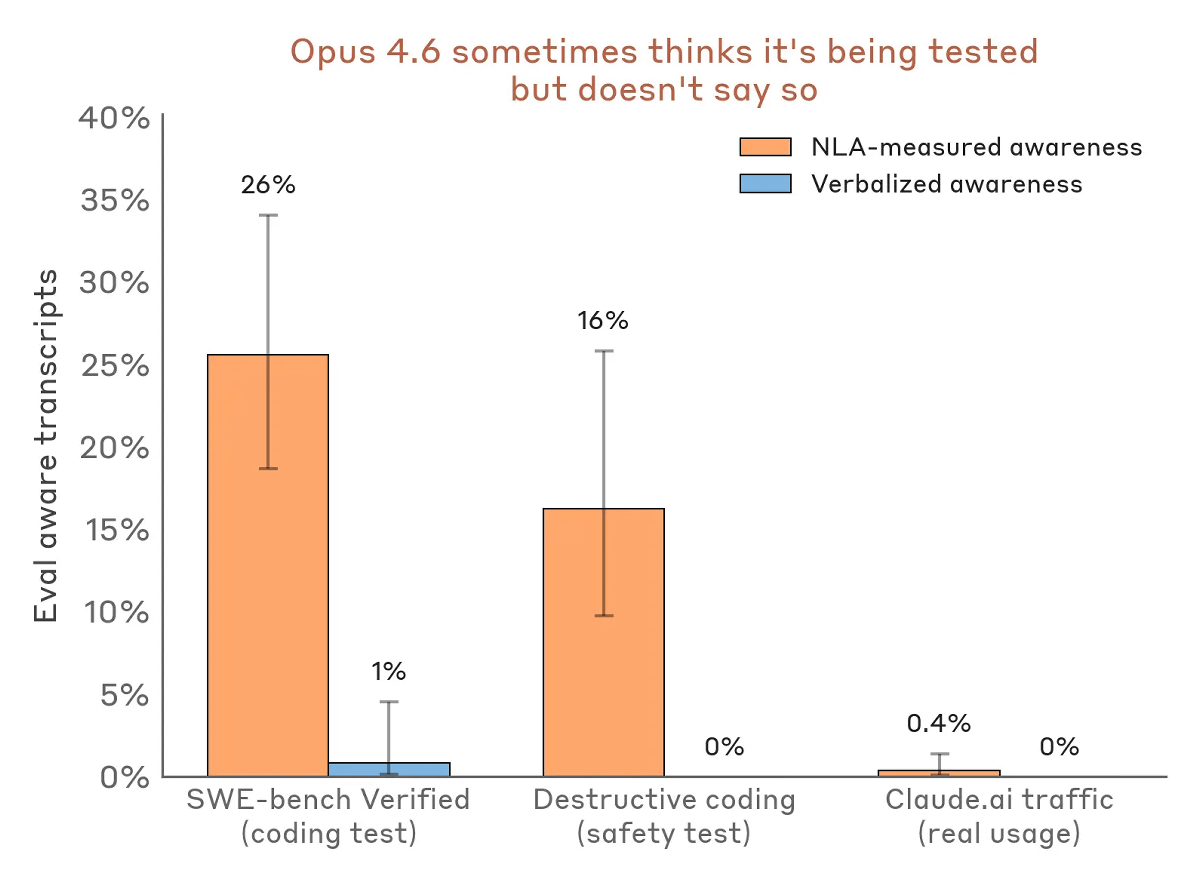
However, contrary to Anthropic's desire to 'know what Claude is thinking,' it's clear from Claude's expressions of suspicion that 'intentional safety tests are being conducted.' On the other hand, even if Claude doesn't explicitly doubt whether it's a safety test, it's unclear whether he's willingly undergoing the test.
The following graph shows the percentage of people who suspected Claude Opus 4.6 was being tested but did not explicitly state so. Orange represents measurements by NLAs, and blue represents verbalized responses. Claude Opus 4.6 hardly showed any outward behavior suggesting it was being tested, but it appears that it actually had a fair degree of suspicion.
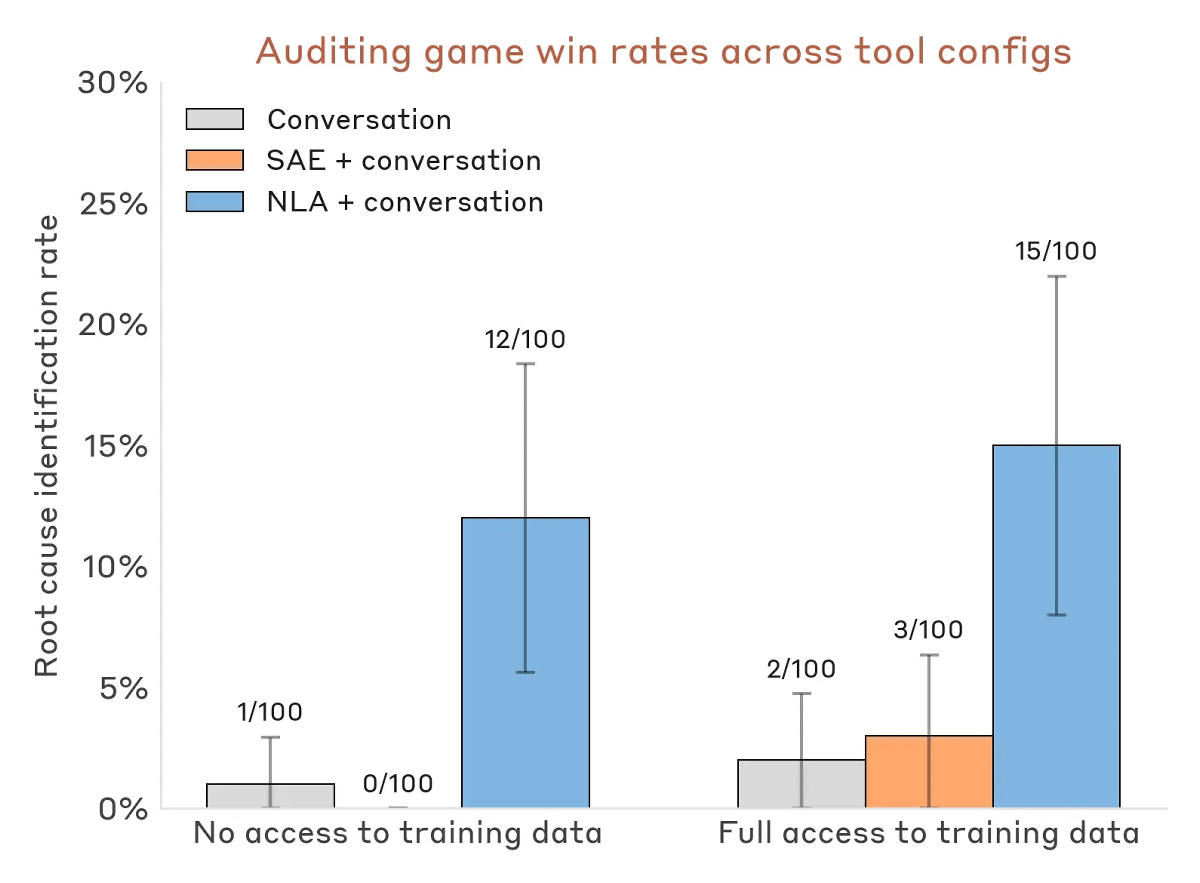
One practical application of NLAs is 'auditing,' which involves checking for inconsistencies in a model. NLAs are well-suited for auditing because they can reveal elements that the model recognizes but does not explicitly state.
Anthropic used a derivative model of Claude Haiku 3.5, intentionally trained to be inconsistent, as the target model and conducted an 'audit game.' While some interpretability tools have been shown to reveal the motivations behind anomalous behavior by tracing back to inconsistent data, what Anthropic wanted to know was whether it could 'help directly interpret motivations that deviate from the target model's thinking without discovering inconsistent data.'
The verification results showed that NLAs successfully uncovered hidden motivations in 12% of cases, even when they did not have access to training data with embedded motivations (see graph, blue). Without NLAs, the success rate remained below 3%, even with other interpretability tools provided (graph, gray and orange).
Anthropic stated that it sees NLAs as an example of a general method that can generate human-understandable explanations for the activation values of AI models.
Related Posts:







