Apple has announced 'RubiCap,' which can create image captions that are better than AI models 10 times larger.

Apple's research team has developed ' RubiCap ,' an AI model that can create more accurate and detailed image descriptions at a much smaller size than existing AI models.
RubiCap: Rubric-Guided Reinforcement Learning for Dense Image Captioning - Apple Machine Learning Research

Apple-trained AI captions images better than models 10× its size - 9to5Mac
https://9to5mac.com/2026/03/25/apple-trained-an-ai-that-captions-images-better-than-models-ten-times-its-size/
Apple's research team, in collaboration with the University of Wisconsin-Madison, has developed a new framework for AI models capable of generating high-density image captions. High-density image captions are the process of generating detailed descriptions at the domain level for every event occurring within an image, rather than simply summarizing the entire image. In other words, by identifying multiple elements and regions within an image and describing them in detail, it is possible to achieve a much richer understanding of the scene than with a general description.
High-density image captions can be used for a variety of purposes, including training visual language models and image generation models that convert text to images. When applied to user-facing features, they can also improve the accuracy of image search and accessibility tools.
According to Apple's research team, the problem is that existing AI-based approaches to training AI models capable of generating high-density image captions are often insufficient in crucial areas. For example, creating the large-scale, expert-level annotations required for training is extremely costly. Another approach is to use synthetic captions with powerful visual-language models, but supervised learning distillation has limitations in terms of output diversity and weak generalization performance . Reinforcement learning has the potential to overcome these constraints, but so far, its results have been limited and it is not considered suitable for open-ended captioning.

Therefore, Apple's research team proposed a new framework. The team randomly sampled 50,000 images from two training datasets,
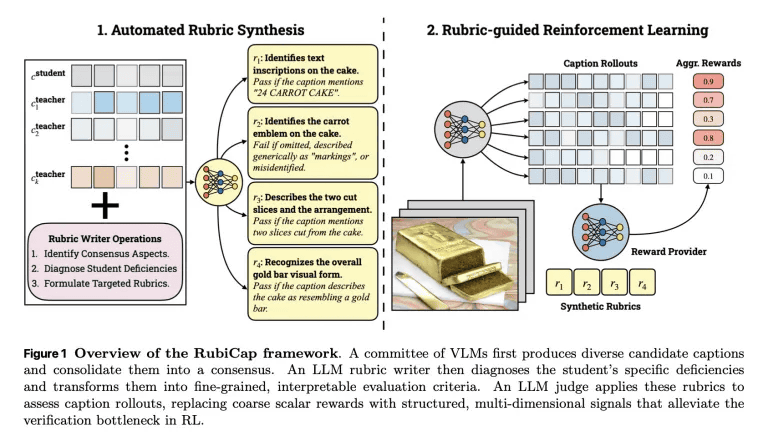
Next, RubiCap uses the Gemini 2.5 Pro to do the following:
1: Comparative analysis of the captions output by each model.
2. Identify the strengths and weaknesses of each model.
3. Based on this, create clear criteria for evaluating captions.
Subsequently, Qwen2.5-7B-Instruct acts as a judge, scoring the captions generated by the AI model based on the criteria created in Step 3, and generating reward signals to be used for training.
As a result, RubiCap can now receive more accurate and structured feedback on what needs to be corrected, enabling it to create more precise captions without relying on a single 'right answer.'
The following image illustrates the feedback loop that RubiCap uses to generate excellent captions.
Ultimately, Apple's research team created three models with different parameter sizes: RubiCap-2B, RubiCap-3B, and RubiCap-7B. They then conducted image captioning benchmark tests to compare the accuracy of generated captions with existing AI models. The results are shown below, with RubiCap-3B (black) demonstrating superior performance compared to competing AI models.
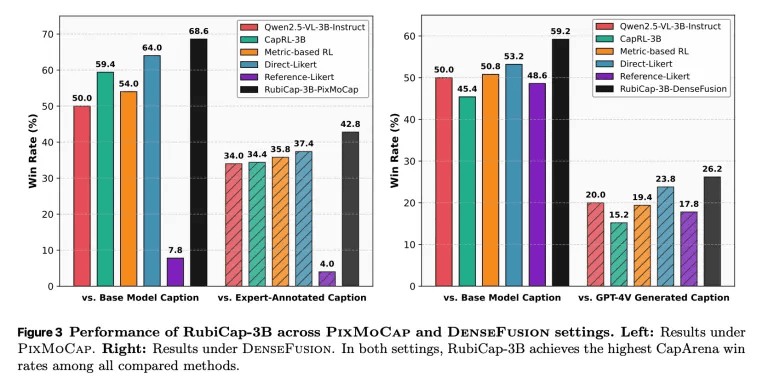
In CapArena , RubiCap achieved higher scores than 'supervised distilled models,' 'traditional reinforcement learning models,' 'models annotated by human experts,' and 'GPT-4V.' In CaptionQA , it also demonstrated excellent word efficiency, with RubiCap-7B, which has the largest parameter size, performing comparably to Qwen2.5-VL-32B-Instruct, which has an even larger parameter size. Notably, using the compact RubiCap-3B as a caption generator allows for the creation of a more powerful pre-trained visual language model than a visual language model trained on captions generated by a proprietary model.
In blind tests, RubiCap-7B was rated as being able to generate the best captions, even when compared to state-of-the-art AI models with parameter sizes of 72 billion and 32 billion. It also demonstrated the lowest rate of hallucination and the highest caption accuracy.
Related Posts:







in AI, Posted by logu_ii