Google develops 'Titans' architecture and 'MIRAS' framework to support AI long-term memory
Google has announced ' Titans ,' an architecture to support long-term memory in AI models, and ' MIRAS ,' a framework.
Titans + MIRAS: Helping AI have long-term memory
The Transformer deep learning model, released by Google researchers in June 2017, revolutionized sequence modeling by introducing attention , a mechanism that allows an AI model to look back at past inputs and prioritize relevant input data. However, because the computational cost increases significantly with sequence length, it is difficult to scale Transformer-based AI models to the 'very long context' required for complete document understanding or genome analysis.
The research community has explored solutions with various approaches, including efficient linear recurrent neural networks (RNNs) and state-space models like Mamba2 . These AI models achieve fast, linear scaling by compressing context to a fixed size. However, fixed-size compression cannot adequately capture the rich information contained in very long sequences.
To address this issue, Google has recently announced two new approaches: Titans and MIRAS . Titans is a specific architecture, and MIRAS is a theoretical framework for generalizing the approach. By combining these two approaches, AI models can incorporate more powerful surprise indicators (unexpected information) during execution, enabling them to maintain long-term memory without dedicated offline retraining.
◆Titans
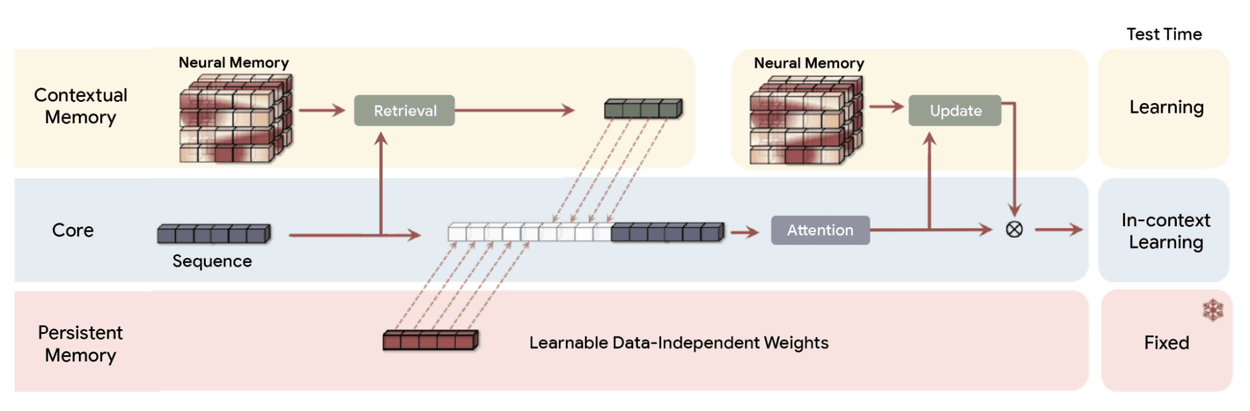
Titans introduces a novel neural long-term memory module that functions as a deep neural network (specifically, a multi-layer perceptron ), unlike the fixed-size vector or matrix memory of traditional RNNs. This memory module provides significantly higher expressive power, allowing AI models to summarize large amounts of information without losing important context. This allows AI models to understand and synthesize the entire story, rather than simply taking notes.
Importantly, Titans doesn't simply store data passively; it actively learns how to recognize and retain important relationships and conceptual themes connecting tokens across inputs. A key aspect of this ability is what Google calls the 'surprise metric.' Psychology teaches us that humans quickly forget routine, predictable events, but are more likely to remember events that break the pattern—even unexpected, surprising, or highly emotional events. Titans' 'surprise metric' mimics this by prioritizing the storage of highly surprising information, which is new to the input, in its long-term memory modules.
◆MIRAS
The major advances in sequence modeling lie in what is essentially the same thing under the hood: highly complex
What makes MIRAS unique and practical is its approach to AI modeling: instead of looking at diverse architectures, it looks at different ways of solving the same problem—ways that efficiently combine new information with old memories without forgetting important concepts.
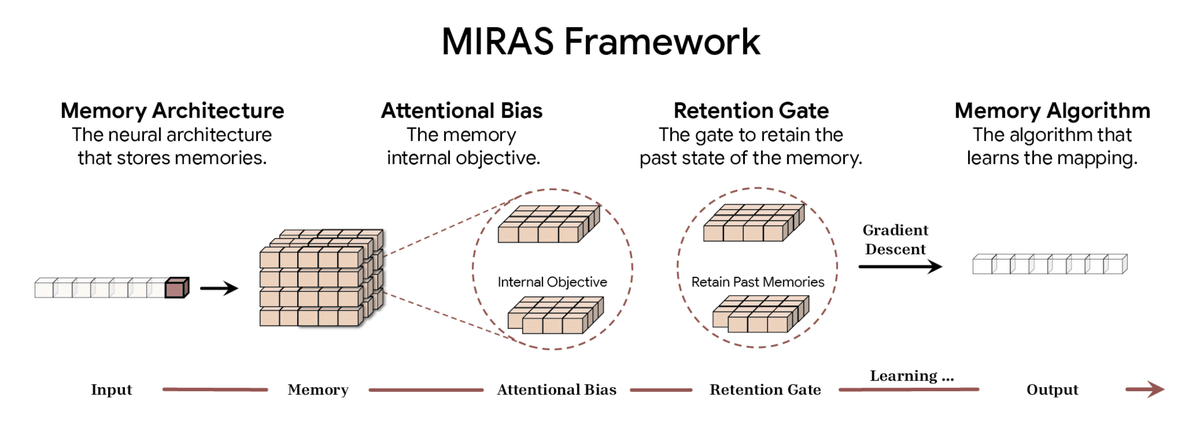
MIRAS defines the sequence model through four main design choices:
Memory architecture: the structure in which information is stored (e.g., vectors, matrices, deep multi-layer perceptrons like Titans)
Attentional bias: The internal learning goal that an AI model optimizes for, determining priorities.
Retention gate: A memory regularizer. MIRAS reinterprets the 'forgetting mechanism' as a specific form of regularization that balances new learning with the retention of past knowledge.
Memory Algorithm: The optimization algorithm used to update memory.
Existing successful sequence modeling relies on mean squared error or dot product similarity for both bias and retention, which tends to make AI models sensitive to outliers and limit their expressive power.
MIRAS overcomes this limitation by providing a generative framework for exploring a richer design space based on the optimization and statistics literature, allowing for the creation of novel architectures with non-Euclidean objective functions and regularization.
Using MIRAS, Google created three attention-free models:
・YAAD
YAAD is a mutation of MIRAS that is designed to be less sensitive to large errors or 'outliers' (e.g., a single typo in a large document). It applies a gentler mathematical penalty for errors ( Huber loss ), so it doesn't overreact to isolated issues. This makes the model more robust when input data is messy or inconsistent.
・MONETA
MONETA is a model that explores the use of more complex and rigorous mathematical penalties (generalization norms). By applying these more disciplined rules to both what the model pays attention to and what it forgets, we hope to build a stronger and more stable long-term memory system overall.
・MEMORA
MEMORA is a model focused on achieving the highest possible memory stability by forcing memory to behave like a strict probability map. This constraint ensures that changes to the memory state are controlled and balanced each time it is updated, ensuring a clean and stable process for integrating new information. Most existing successful sequence models rely on mean squared error or dot product similarity for both bias and retention, which makes the model sensitive to outliers and limits its expressive power.
Google's research team rigorously compared Titan and its MIRAS derivatives, YAAD, MONETA, and MEMORA, with leading architectures such as Transformer++, Mamba2, and Gated DeltaNet. Furthermore, by testing Titans on genome modeling and time series forecasting, the team validated the generality of each AI model, demonstrating that the architecture can effectively generalize beyond text processing.
The introduction of Titans and MIRAS represents a major advance in sequence modeling. By using deep neural networks as memory modules that learn as data is input, these approaches overcome the limitations of fixed-size recurrent states. Furthermore, MIRAS provides a powerful theoretical unification, revealing the connection between online optimization, associative memory, and architectural design. Google explains Titans and MIRAS as follows: 'By transcending the standard Euclidean paradigm, this research opens the door to a new generation of sequence models that combine the efficiency of RNNs with the expressive power required in the era of long-context AI.'
Related Posts:








in AI, Posted by logu_ii