A heated debate on the topic of 'AI tools need to be disclosed for contributions'
AI tooling must be disclosed for contributions by mitchellh · Pull Request #8289 · ghostty-org/ghostty · GitHub
https://github.com/ghostty-org/ghostty/pull/8289
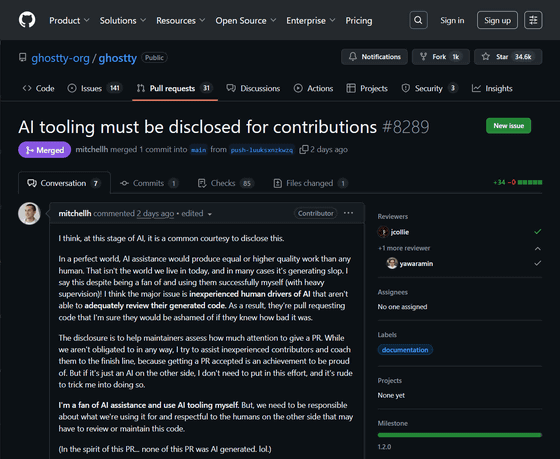
Hashimoto, a developer at HashiCorp, posted a comment in the GitHub repository for Ghostty , an open-source cross-platform terminal emulator, saying that 'AI tools must be disclosed for contributions.'
'At this stage of AI, I think it's common courtesy to make the code public,' Hashimoto said. 'In an ideal world, AI assistants would produce results of equal or better quality than humans. However, this is not the case in modern society, and AI often produces shoddy results. I say this despite being a fan of AI myself and using it successfully under strict supervision. I think the biggest problem is that inexperienced humans operating AI are unable to properly review the code generated. As a result, many people submit pull requests for code without knowing that it is of poor quality.'
'I disclose information to help maintainers determine how much attention they should pay to a pull request. While disclosure isn't mandatory, I strive to support less experienced contributors and guide them to their goals. Having a pull request approved is a proud achievement. However, if the other party is simply an AI, I don't need to put in that much effort, and it would be rude to trick me into doing so,' Hashimoto said. 'I'm a fan of AI assistants and use AI tools. But you need to be responsible for what you use AI for and for the people who may have to review and maintain that code.' He emphasizes the importance of disclosure.

Hashimoto's comment received 478 thumbs-up emojis, 3 thumbs-down emojis, 11 laughing emojis, 8 joyful emojis, and 124 heart emojis, showing a large amount of support on GitHub.
Hashimoto's argument that 'AI tools need to be disclosed for contribution purposes' has also become a hot topic on the social message board Hacker News.
AI tooling must be disclosed for contributions | Hacker News
https://news.ycombinator.com/item?id=44976568
'The provenance of information matters. Large-scale language models (LLMs) cannot authenticate developer certificates (DCOs). Even honest developers cannot authenticate the DCOs of code generated by LLMs, let alone those of LLMs trained on code of unknown provenance. LLMs are well known to generate verbatim or near-verbatim copies of training data, most of which cannot be used without attribution. Furthermore, they may have more onerous licensing requirements. It's also well known that LLMs don't 'understand' semantics , meaning they never make changes for legitimate reasons,' one user wrote . 'For maintainers to accept code generated by LLMs not only puts the entire community at risk, but also endorses a power structure that disregards consensus.'
Another user commented, 'AI also creates intellectual property infringement. We just pretend it doesn't exist. If someone came to you and said, 'Good news, I have all the code from open source projects in this space memorized and can repeat it on command,' you'd be wise to ban them from working on code at your company. But with AI, we invent a bunch of rationalizations , and pretend we never said they were just loosely laundering GPL and other code in a way that makes their very existence harmful to IP-based companies.'
Related Posts:








in Software, Posted by logu_ii