A detailed explanatory movie about 'Attention', the mechanism that produced many high-performance AIs such as ChatGPT, will be released
3Blue1Brown, a website that explains various mathematical topics in the form of videos, provides an explanation of ' Attention ,' the heart of the 'Transformer' structure that shapes AI such as ChatGPT.
3Blue1Brown - Visualizing Attention, a Transformer's Heart | Chapter 6, Deep Learning
The basic job of large-scale language models, which can be said to be the essence of AI, is to 'read a sentence and predict the next word.'
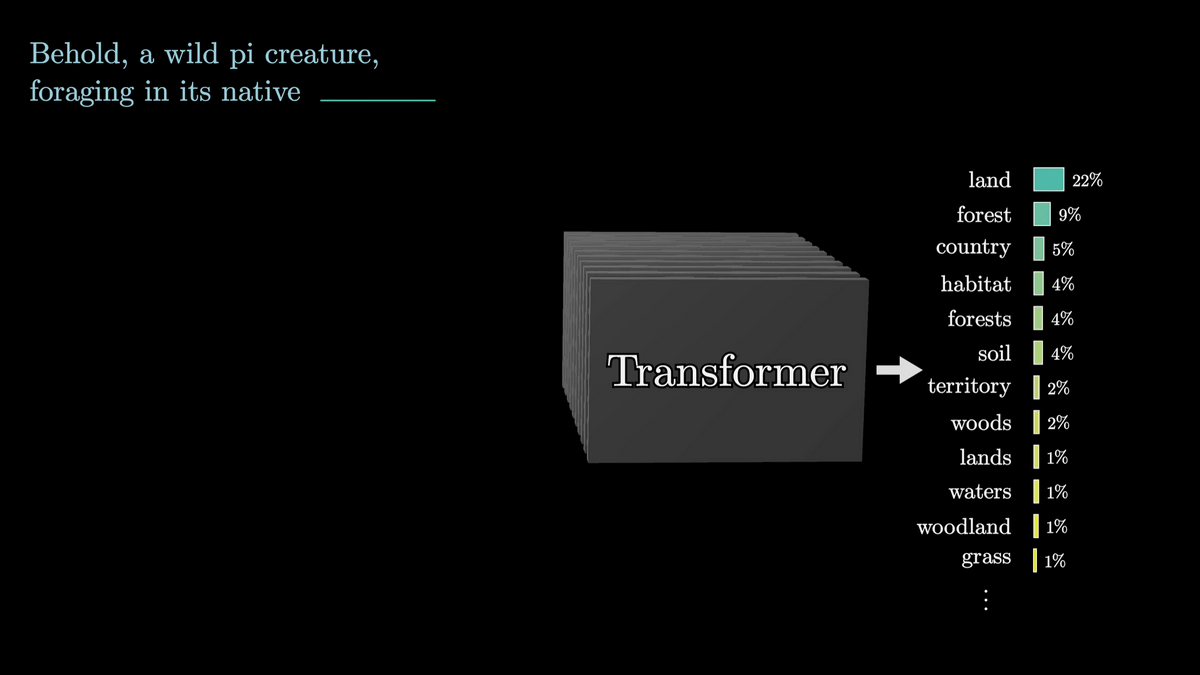
A sentence is broken down into units called 'tokens', and large-scale language models process these units. In reality, there is not one token for each word, but 3Blue1Brown simplifies the explanation by saying 'one word is one token'.

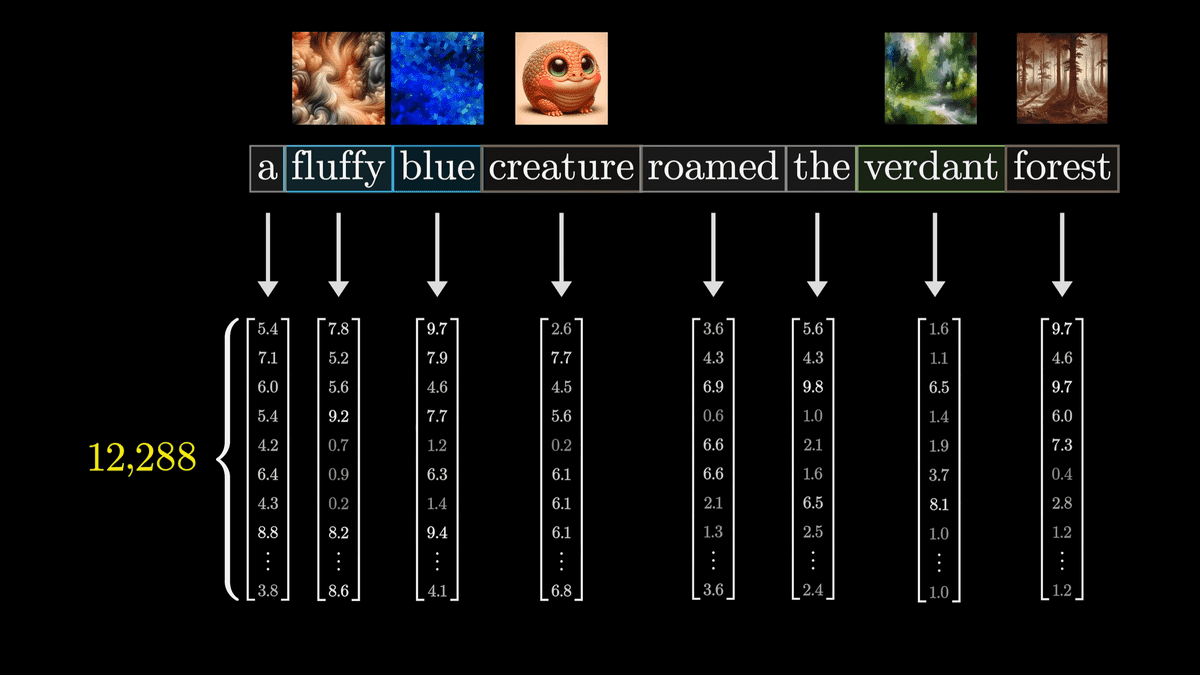
Large-scale language models first associate each token with a high-dimensional vector.
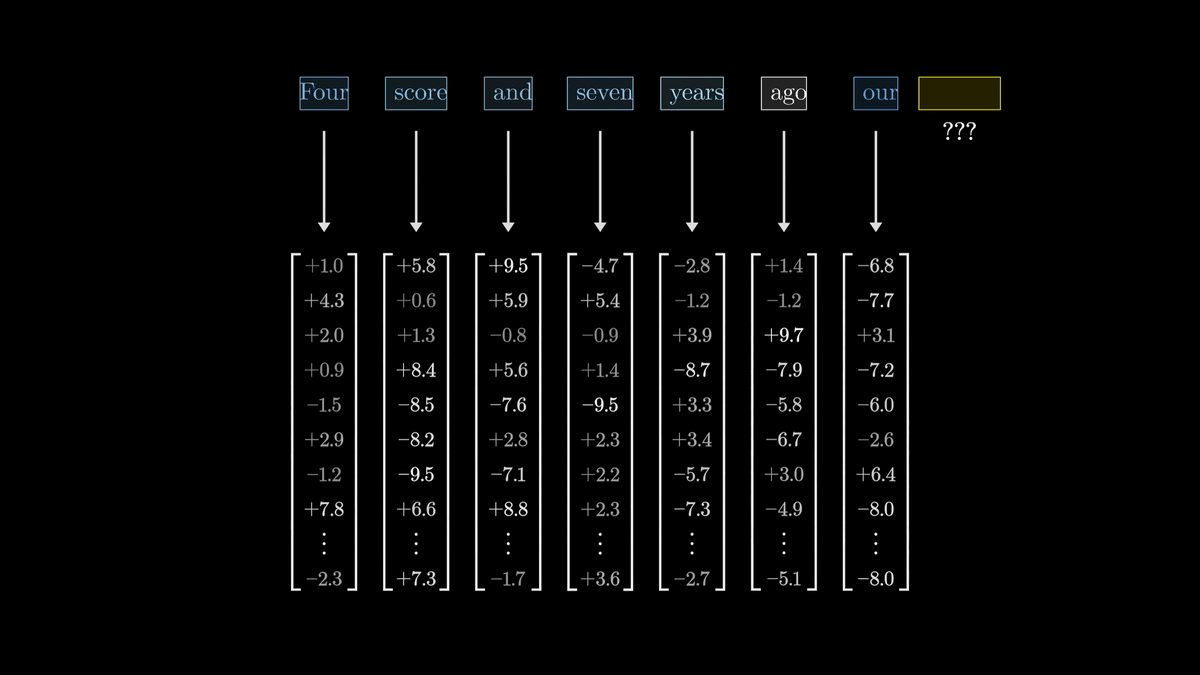
This act is called embedding.
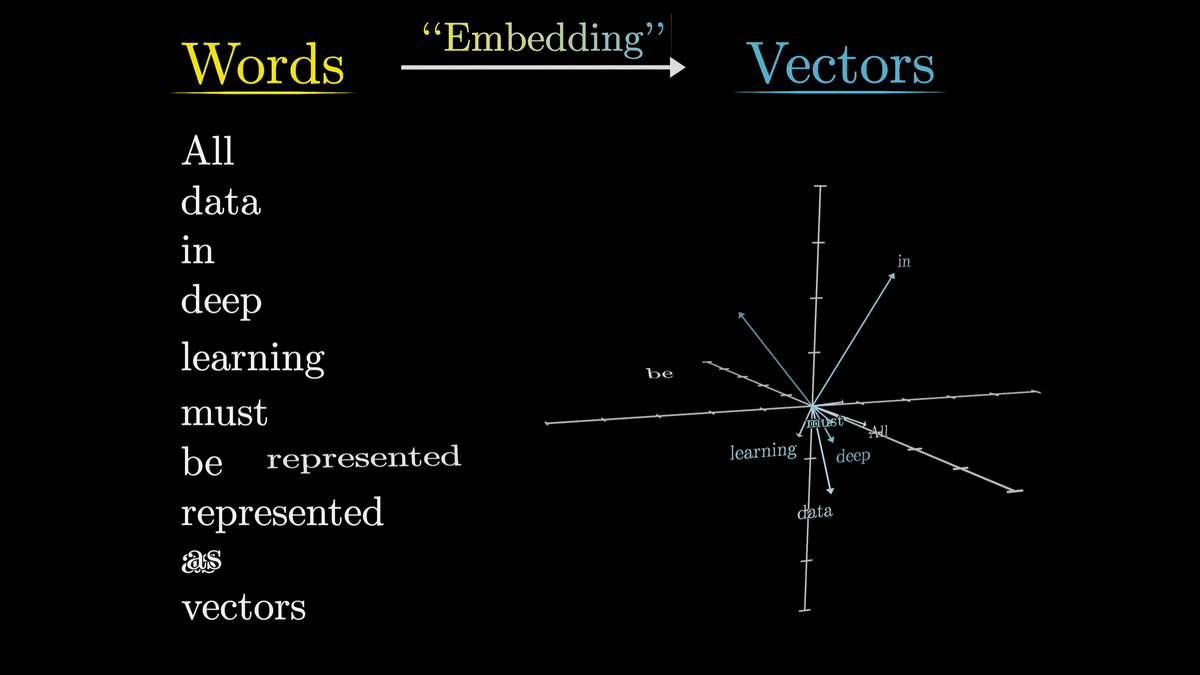
Looking at one aspect of high-dimensional vector space, we see that there are various semantic associations, such as 'daughter-son' and 'woman-man' having similar vectors.
However, the same word can have different meanings depending on the context, making it difficult to embed an appropriate word based on each word alone. The role of the Transformer is to embed the appropriate meaning of a word using the surrounding context.

A simple embedding is just a translation table, so the same word 'mole' will associate with the same high-dimensional vector.
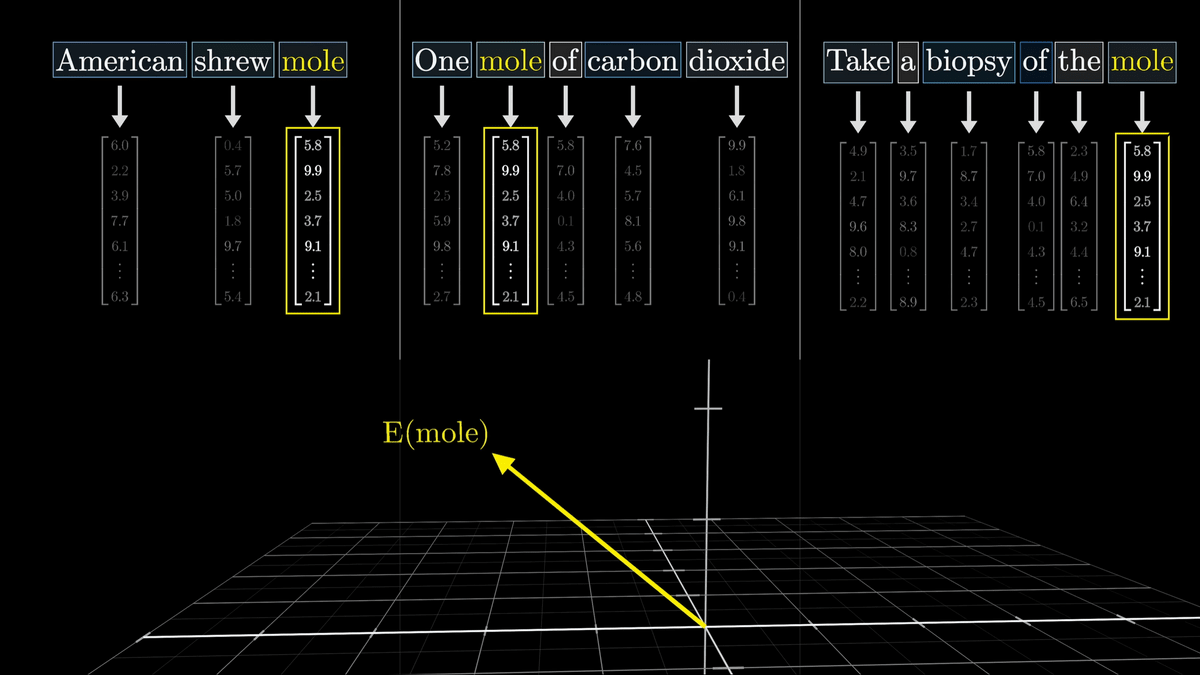
Here, we want attention to calculate the degree of relevance with surrounding words and adjust the vector appropriately.
By doing so, even for the same single word, an appropriate vector can be generated based on the surrounding context.

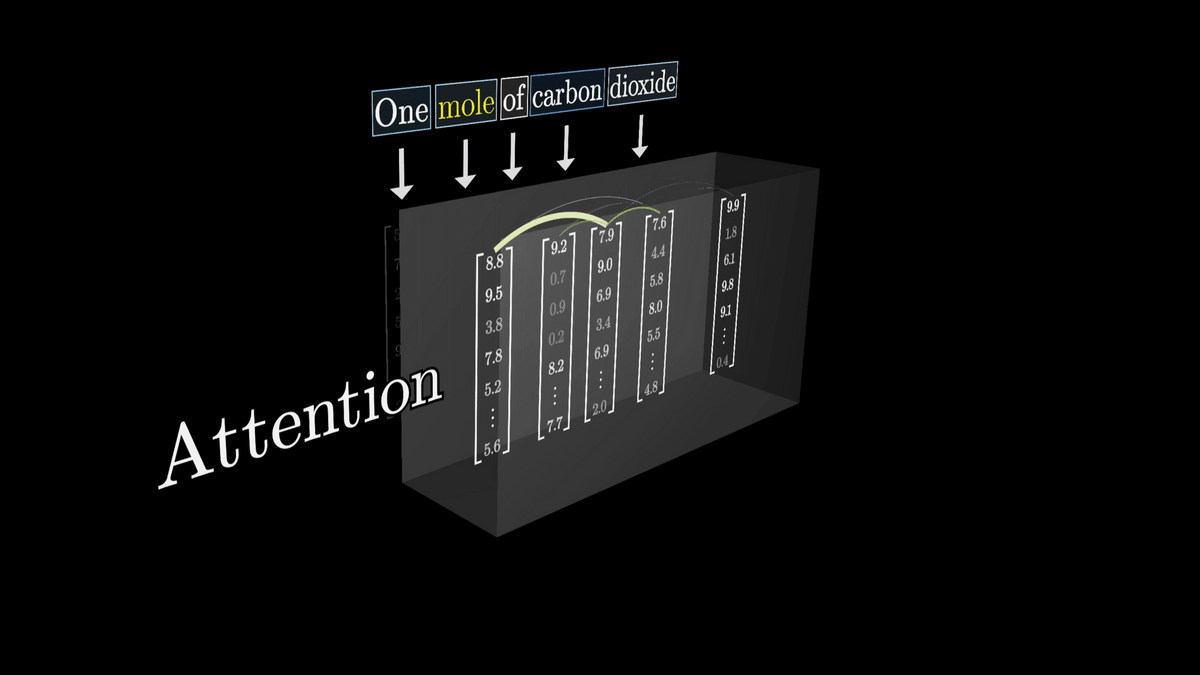
In addition to adjusting the vectors of words with clearly defined meanings, attention also adjusts vectors of ambiguous meanings, such as 'tower' and 'Eiffel Tower,' to vectors with more specific meanings.

Attention can pull information encoded in other word embeddings and adjust the word embeddings.
In some cases, the word may derive meaning from words that are quite far away, or it may pack a lot of information into a single word.

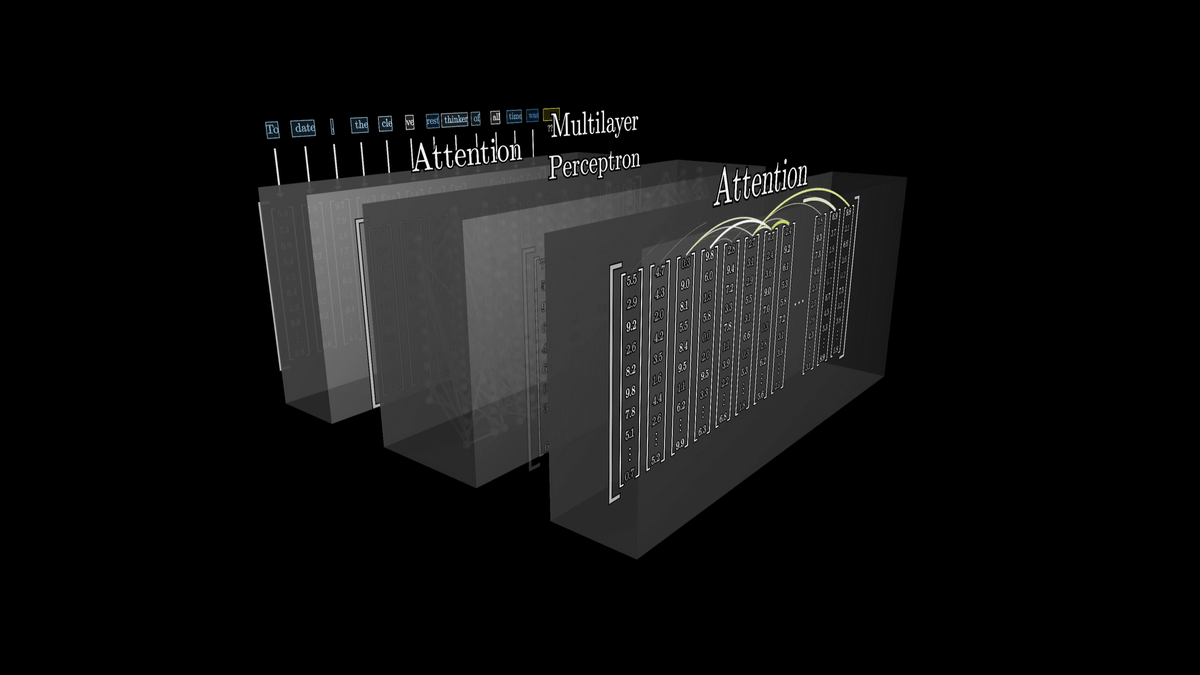
After a large number of vectors have been run through a network containing many different attention blocks, it is the function of the last vector in the sequence that does the job of 'predicting the next word.'
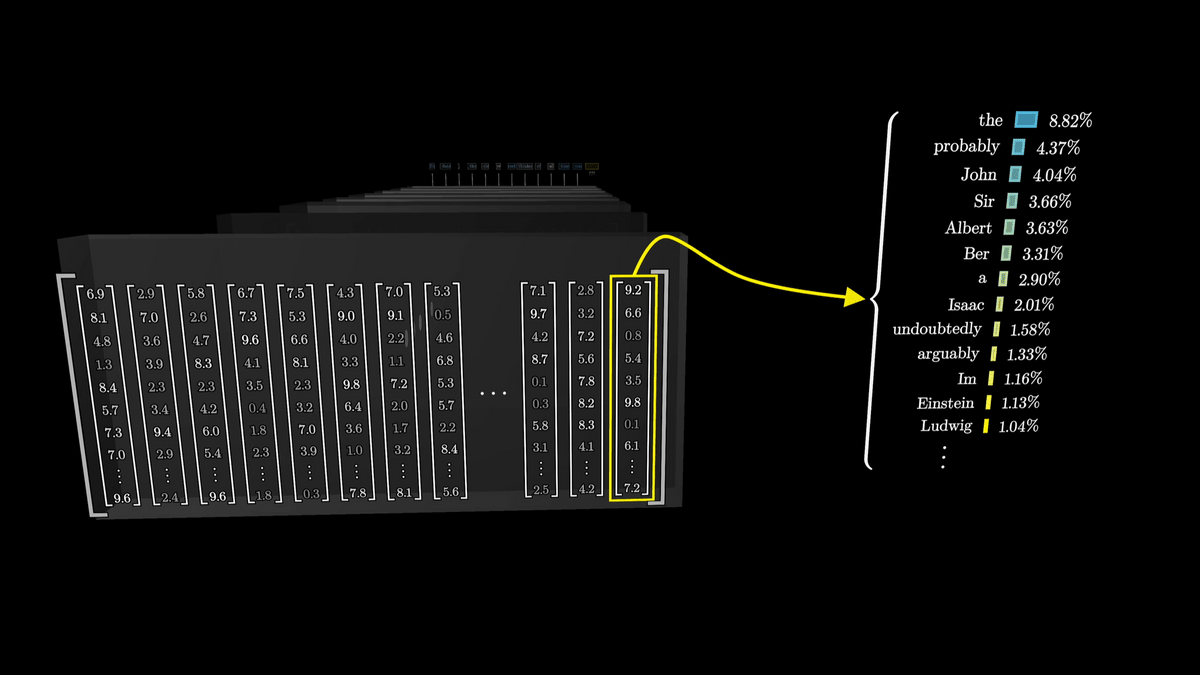
For example, if you are given the entire text of a mystery novel and the task is to predict what comes next after the final line, 'therefore, the murderer was,' then the vector embedding the last token, 'was,' needs to be updated by all attention blocks so that it contains a huge amount of information.

In this case, we need to somehow fill in all the relevant information in a single input context window.

Now that we understand the job of attention, let's consider how to calculate it using a simple example. Here, we consider how to update the noun vector based on the content of the adjective when the form is 'adjective + noun.'

In this simple example, we look at the calculation of 'single head of attention' rather than 'multi-headed attention'.

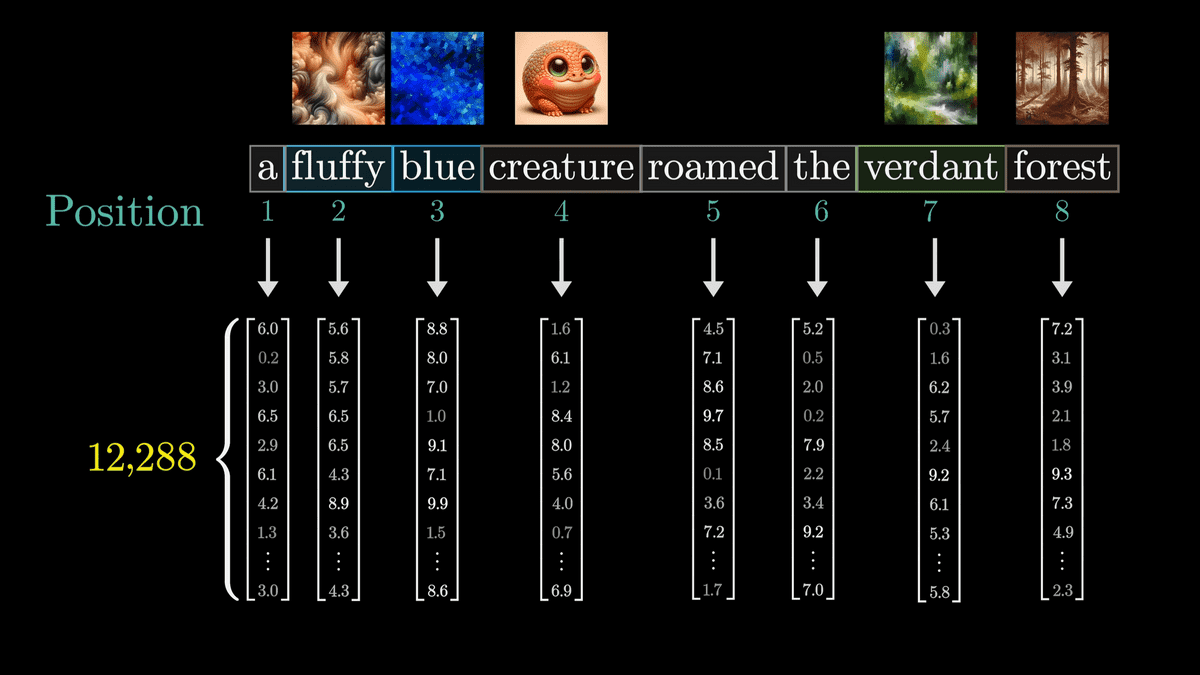
As we saw at the beginning, each word is first vectorized based on a context-free correspondence table.
However, this representation is not accurate, and in reality, not only words but also location information are vectorized.
Let's represent the generated vector as 'E'. In this example, the goal is to generate a new vector 'E4'' that incorporates the meanings of adjectives such as 'E2' and 'E3'.
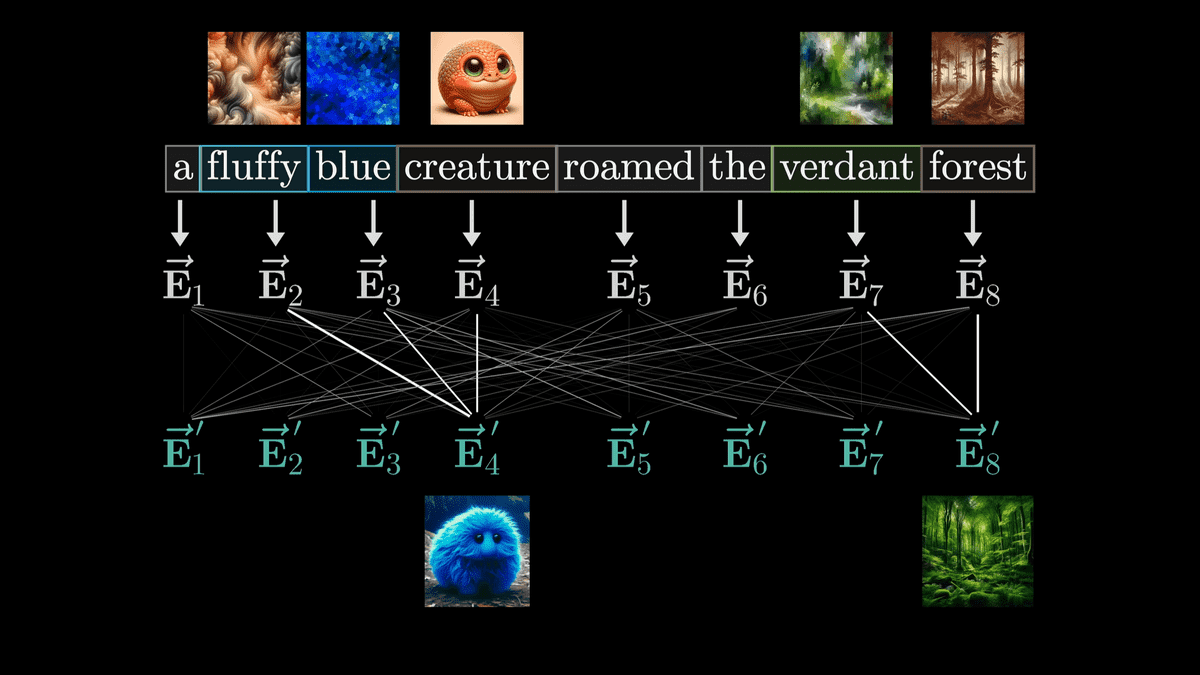
Also, we want to calculate E4' in the form of 'matrix and vector multiplication', because in the world of deep learning, the matrix parameters can be trained based on data.

In addition, since the actual behavior of deep learning is complex and difficult to analyze, 3Blue1Brown prioritizes ease of understanding and uses the example of 'updating the noun vector based on the adjective vector.'
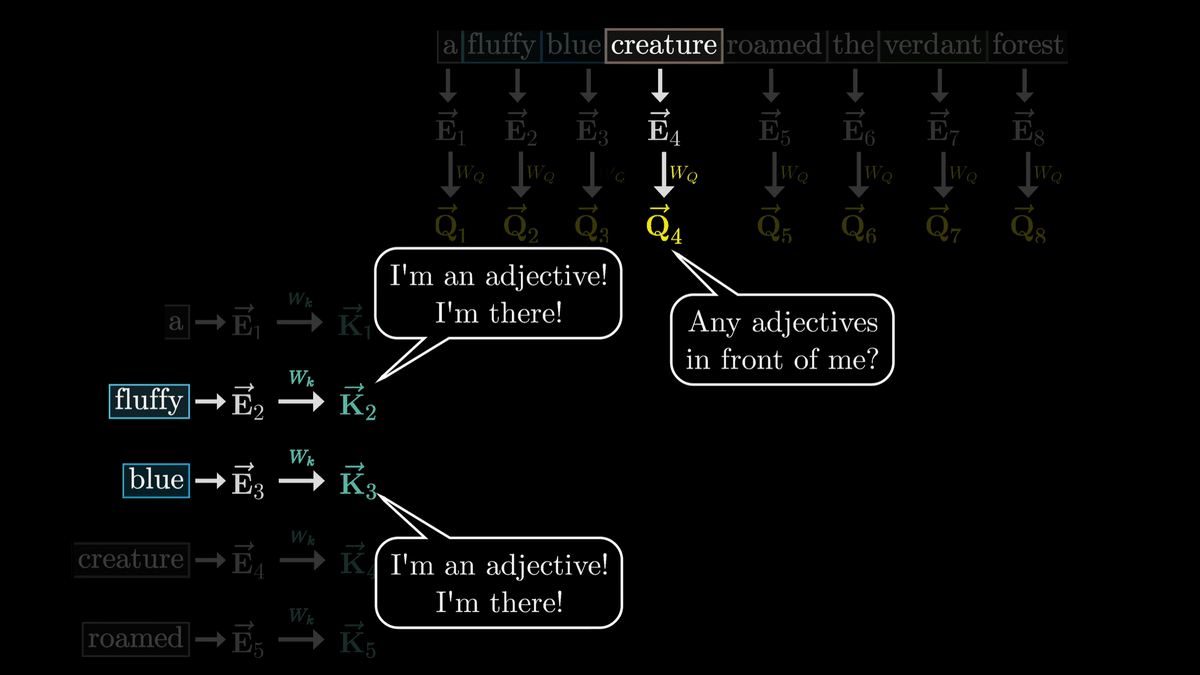
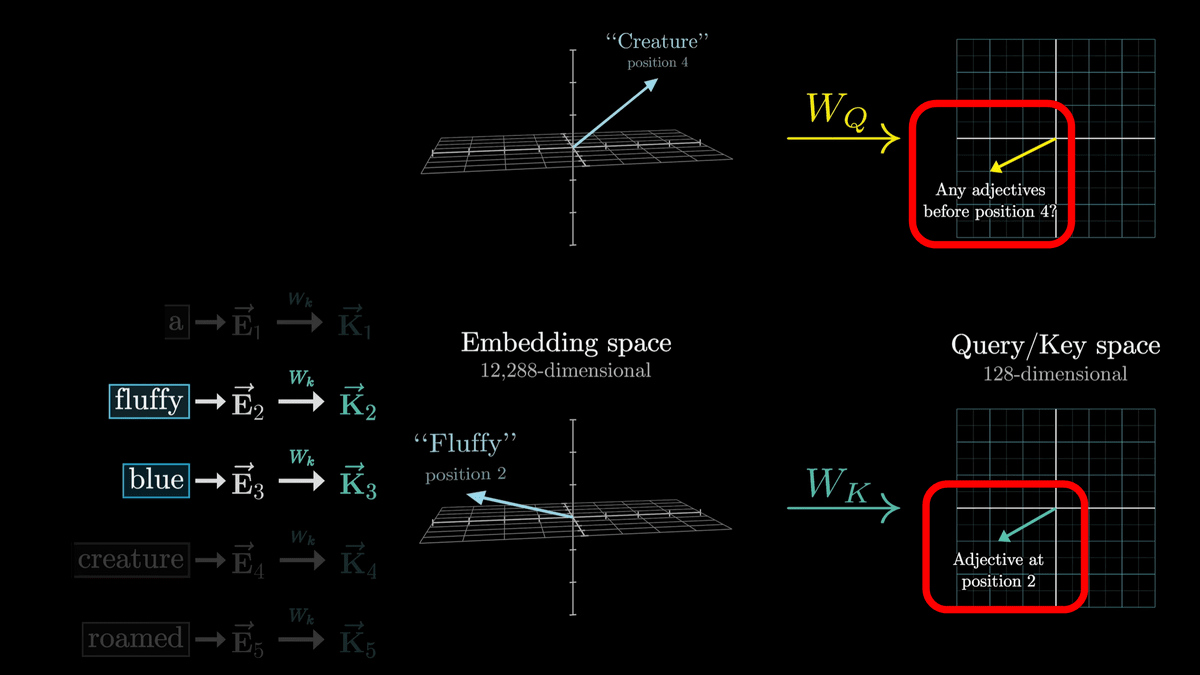
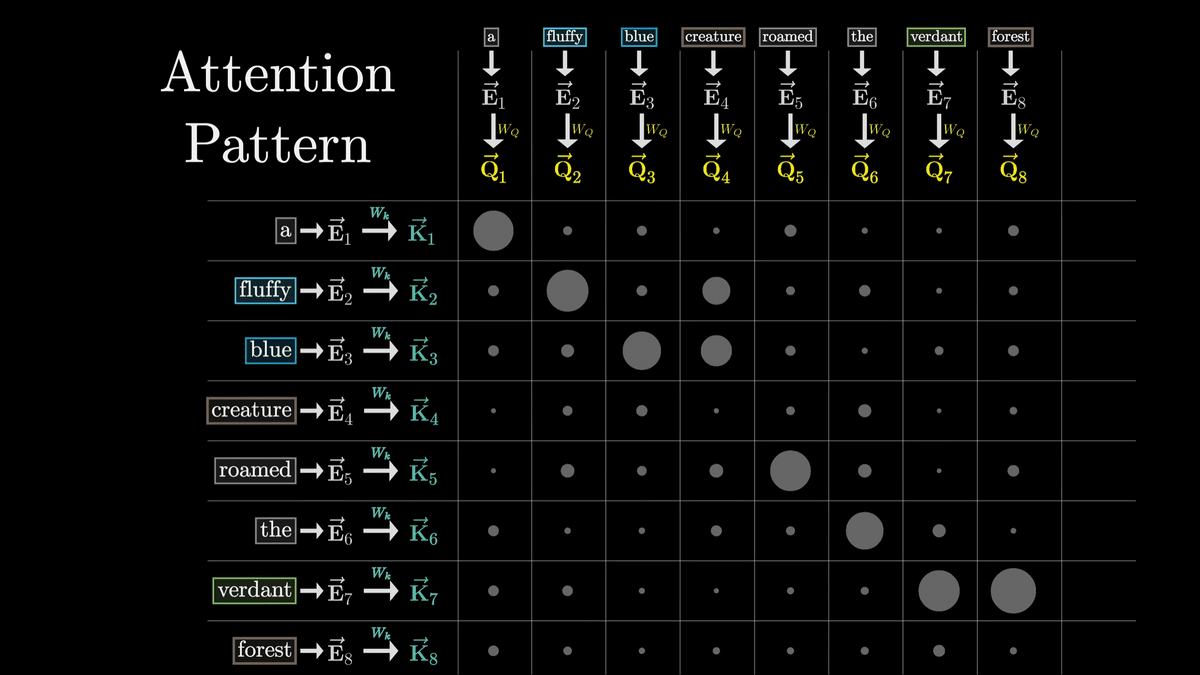
Now, in the first step, we'll look at how a noun asks, 'Is there an adjective in front of me?' and the adjectives respond, 'Yes, there are!'
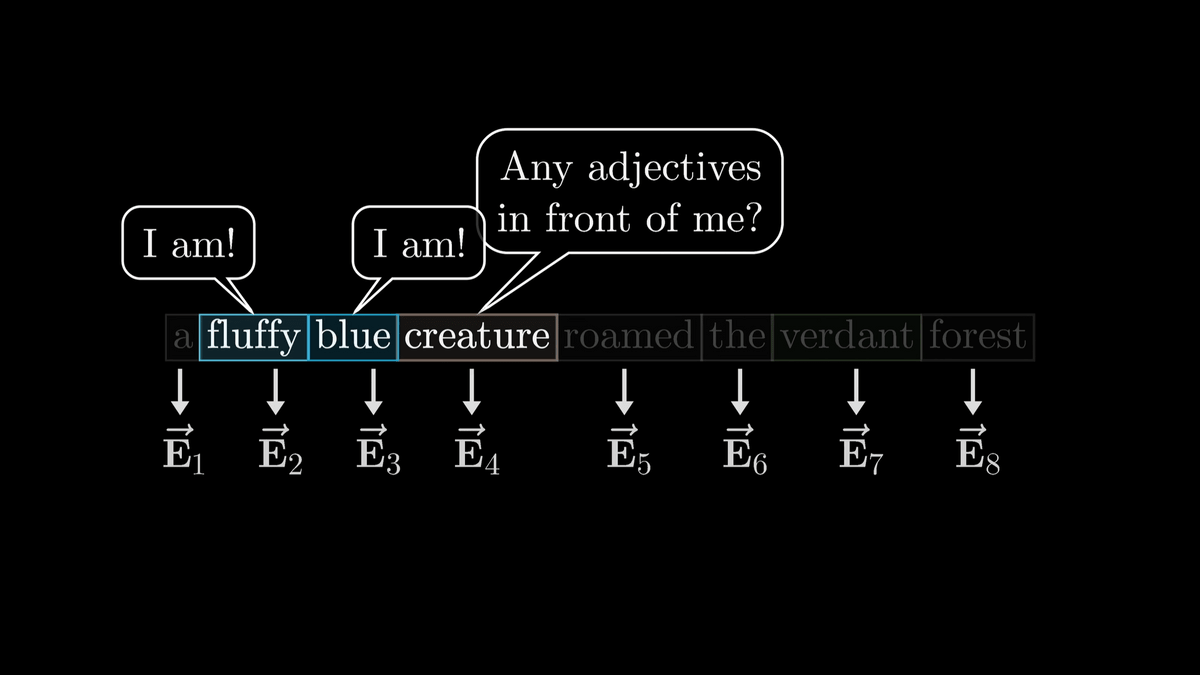
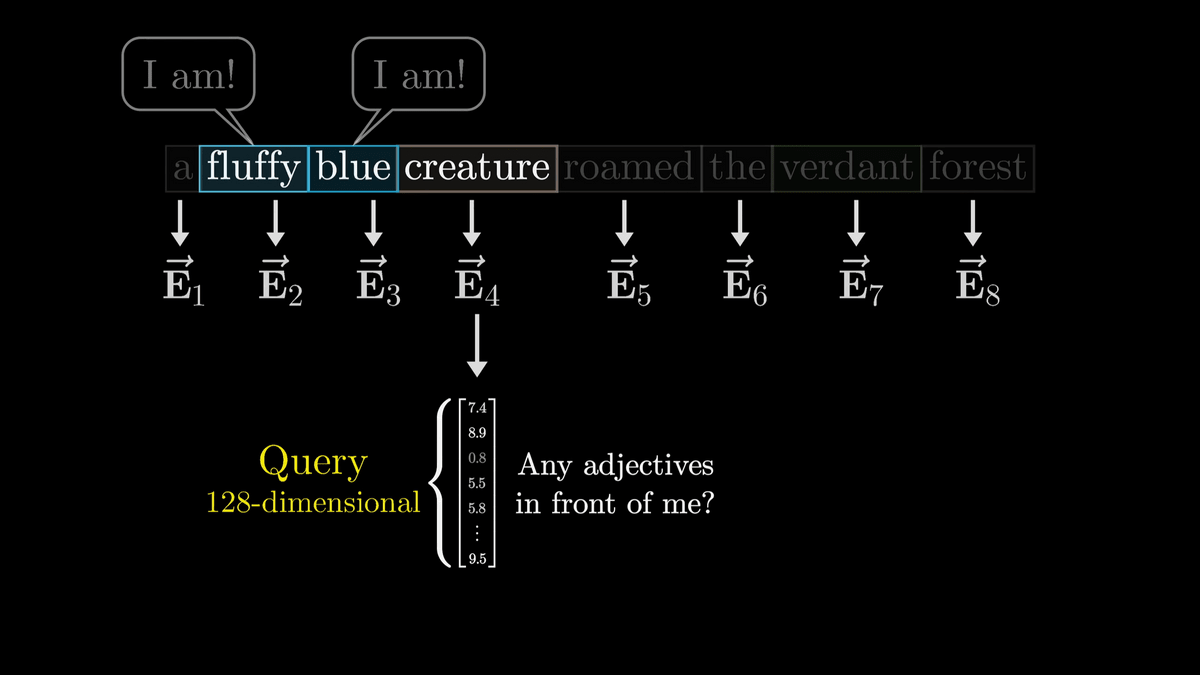
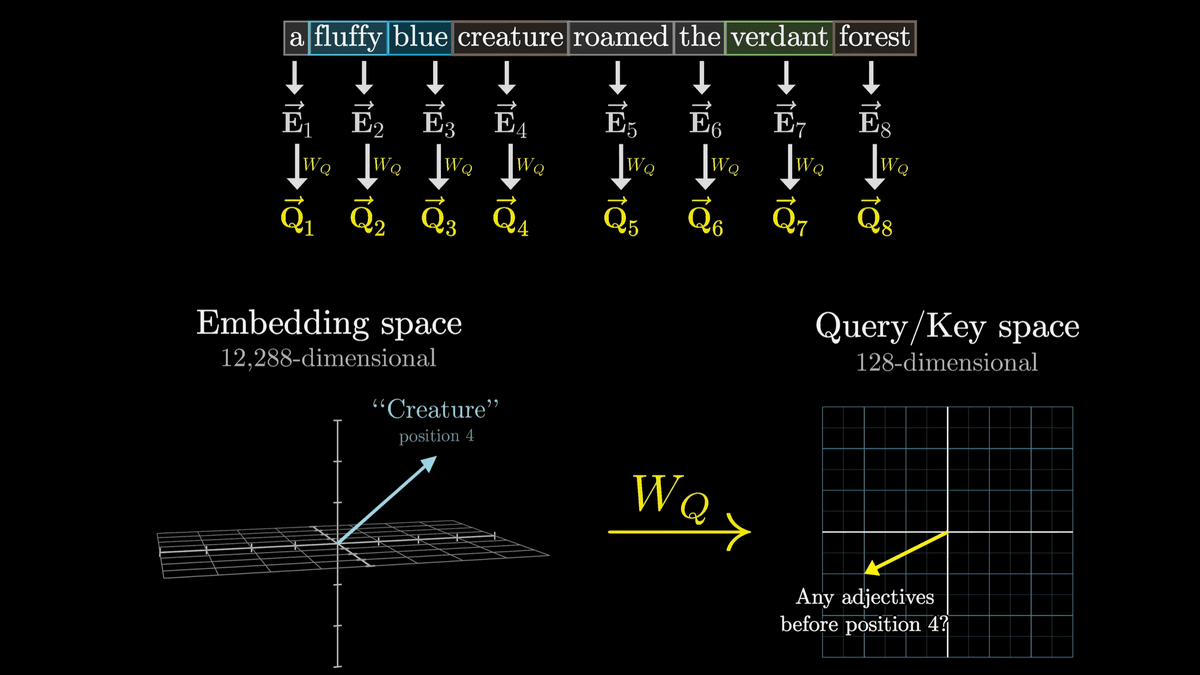
Noun questions are encoded into a vector called 'Query', which has 128 dimensions, which is much smaller than the word embedding vector.
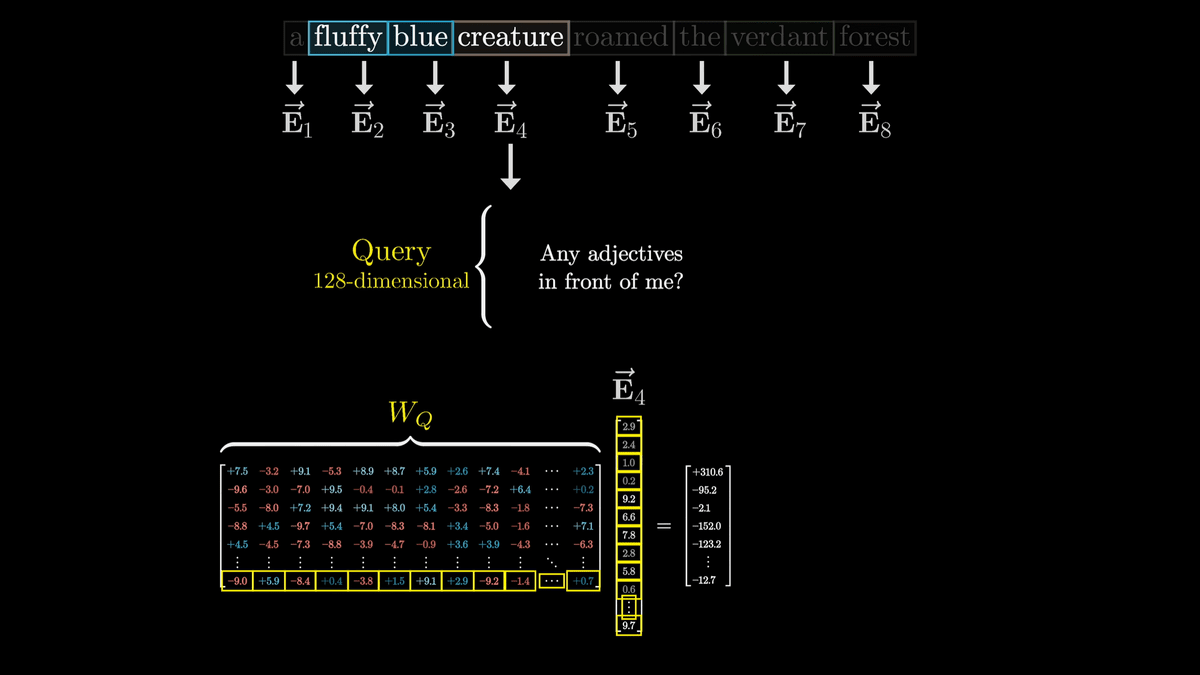
The query is calculated by multiplying the matrix represented by 'W_Q' and 'E4' as shown below.
If we use arrows to represent the operation of multiplying a matrix and updating a vector in this way, it looks like the diagram below, in which the 'E' vector with each token embedded in it is converted by 'W_Q' into one 'Q' vector for each token.
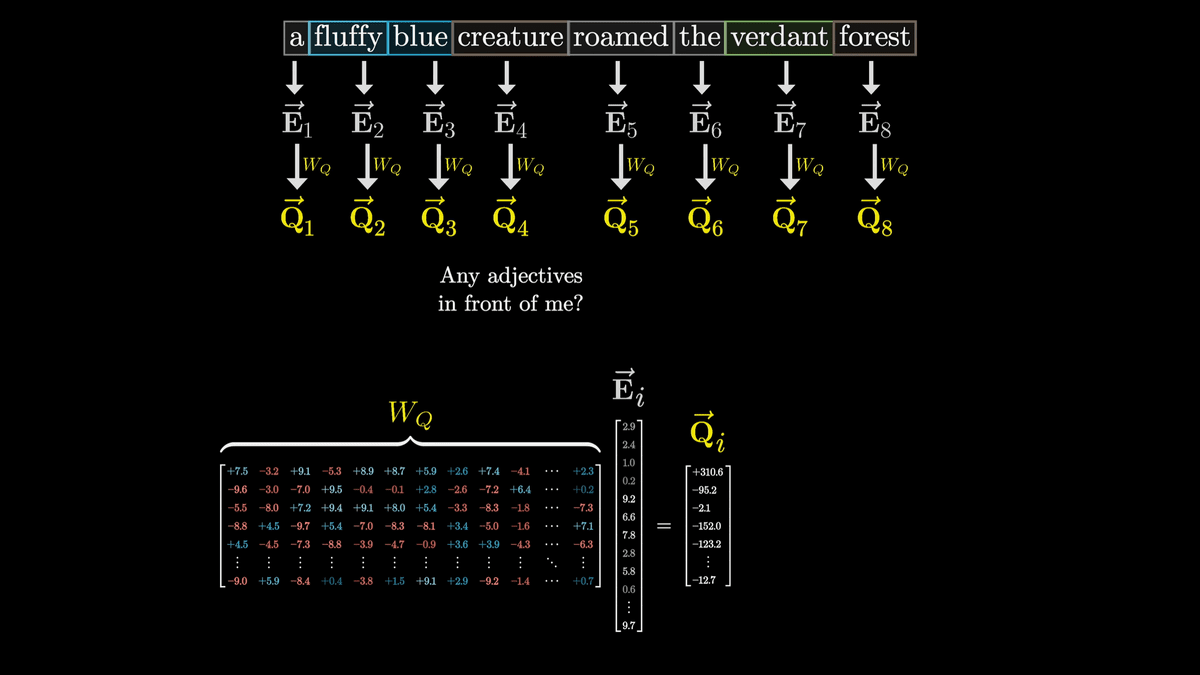
W_Q is a parameter that is adjusted through training, and it is difficult to analyze its actual behavior, but for the sake of clarity, we consider it to convert a vector with noun tokens embedded into a vector that represents the question 'Is there an adjective in front of me?'
Now, just as we used W_Q to generate a Q vector for each token, we use W_k to generate a K vector for each token, where K is called the Key vector.
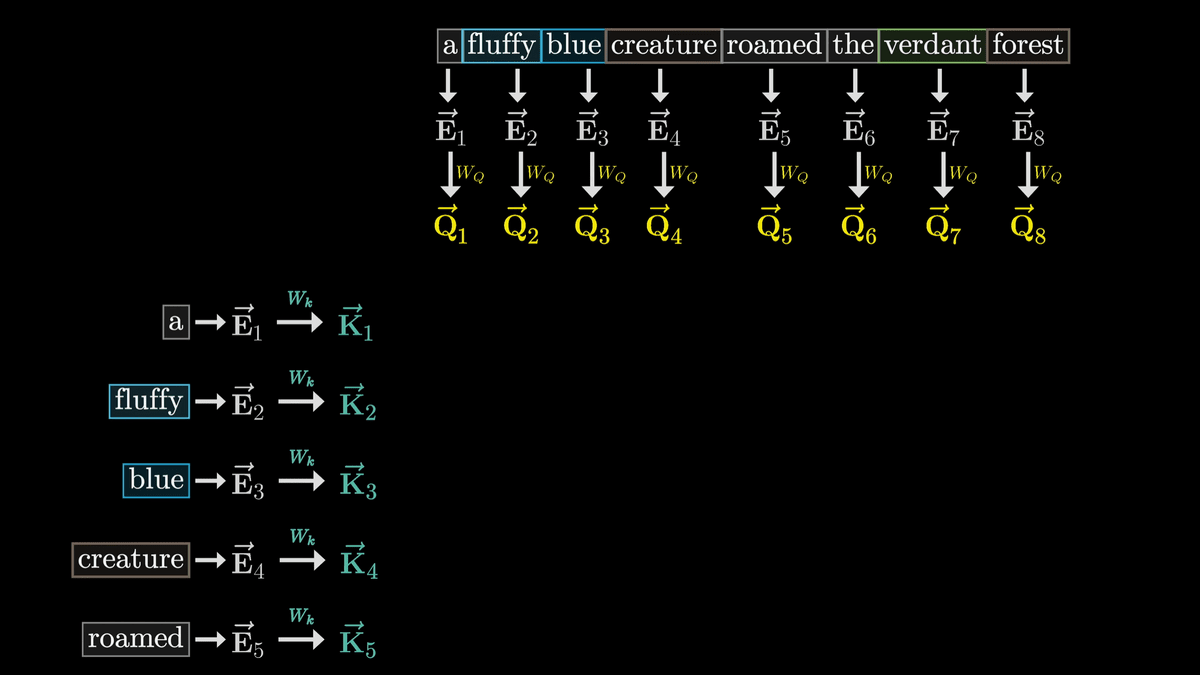
Conceptually, we can think of each K vector as answering a question asked by the Q vector.
Like W_Q, W_k is a trainable parameter matrix that maps the embedding vector of each token into a smaller dimensional Query/Key space.
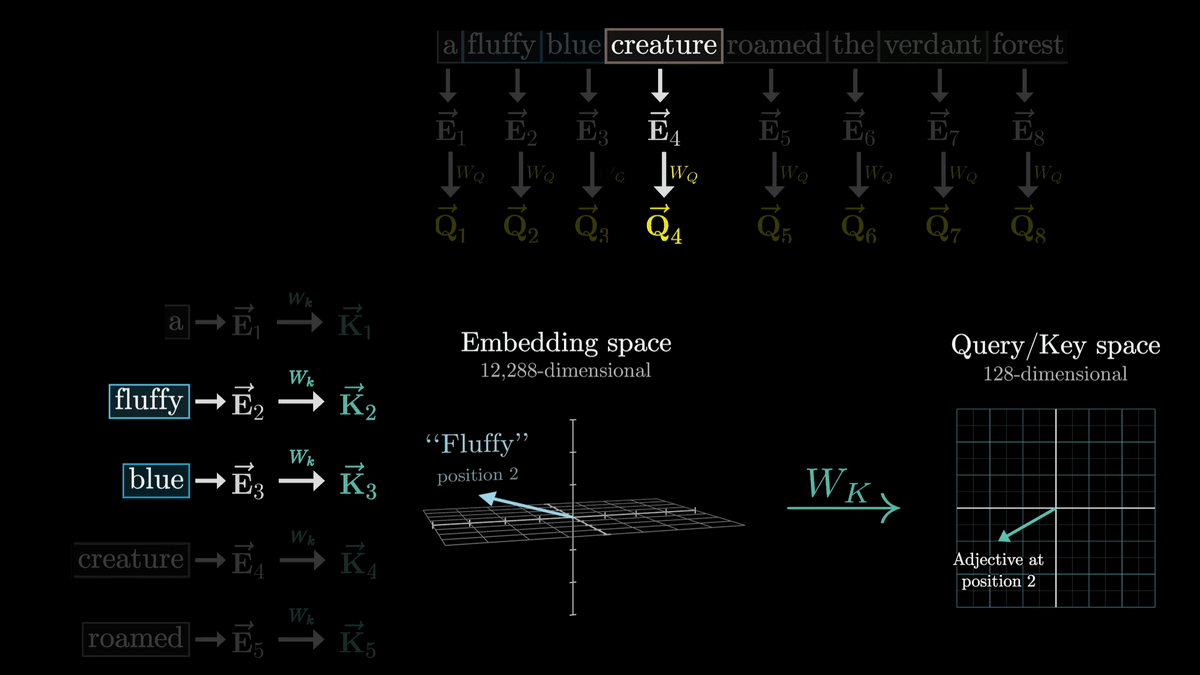
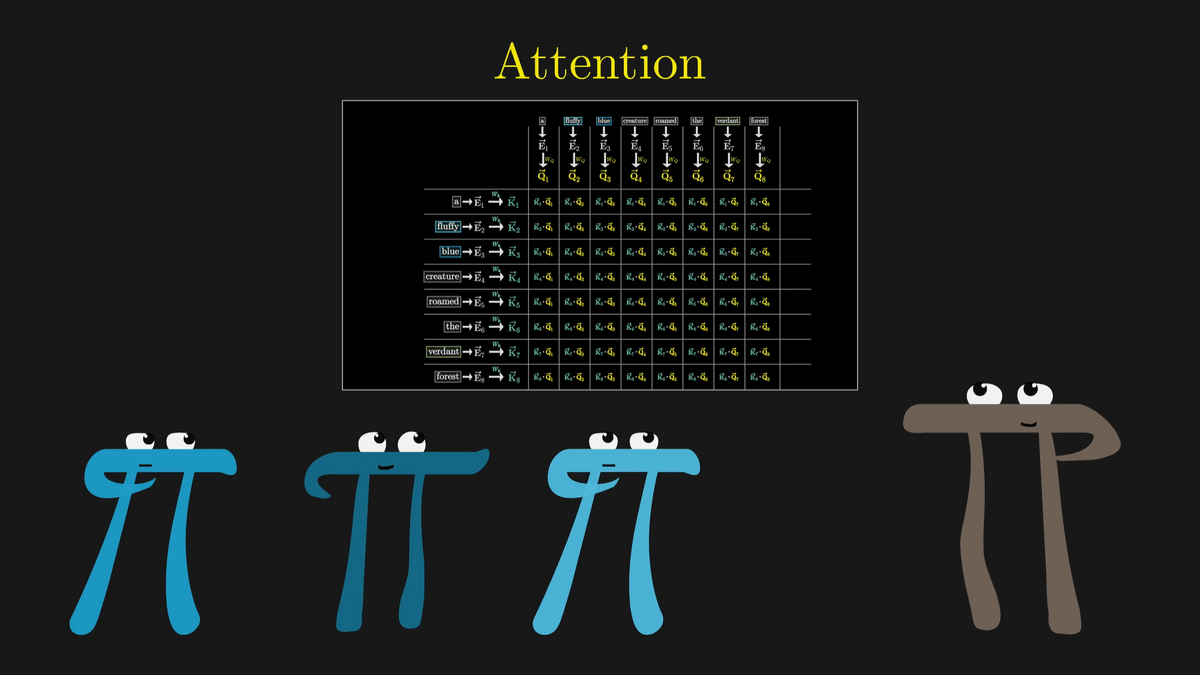
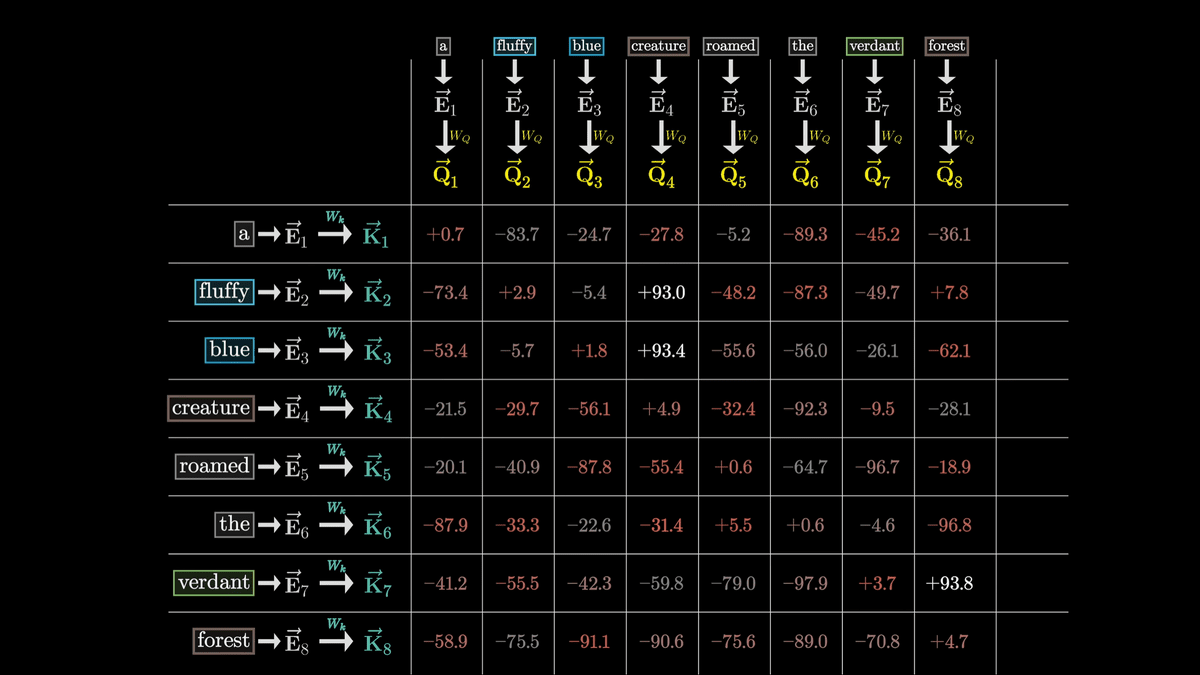
Whether the Key responds to a query is determined by whether the Q vector and K vector are similar vectors.
This similarity can be calculated by taking
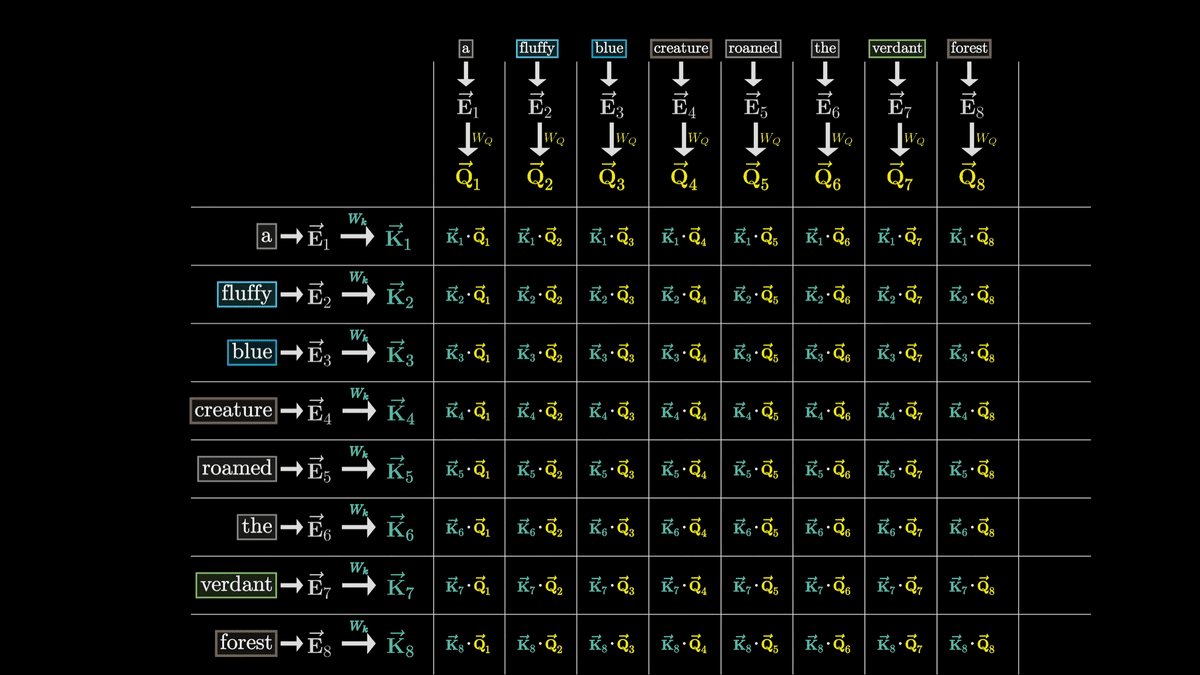
In this case, we can see that Q4, K2, K3, and Q8 and K7 are similar vectors.
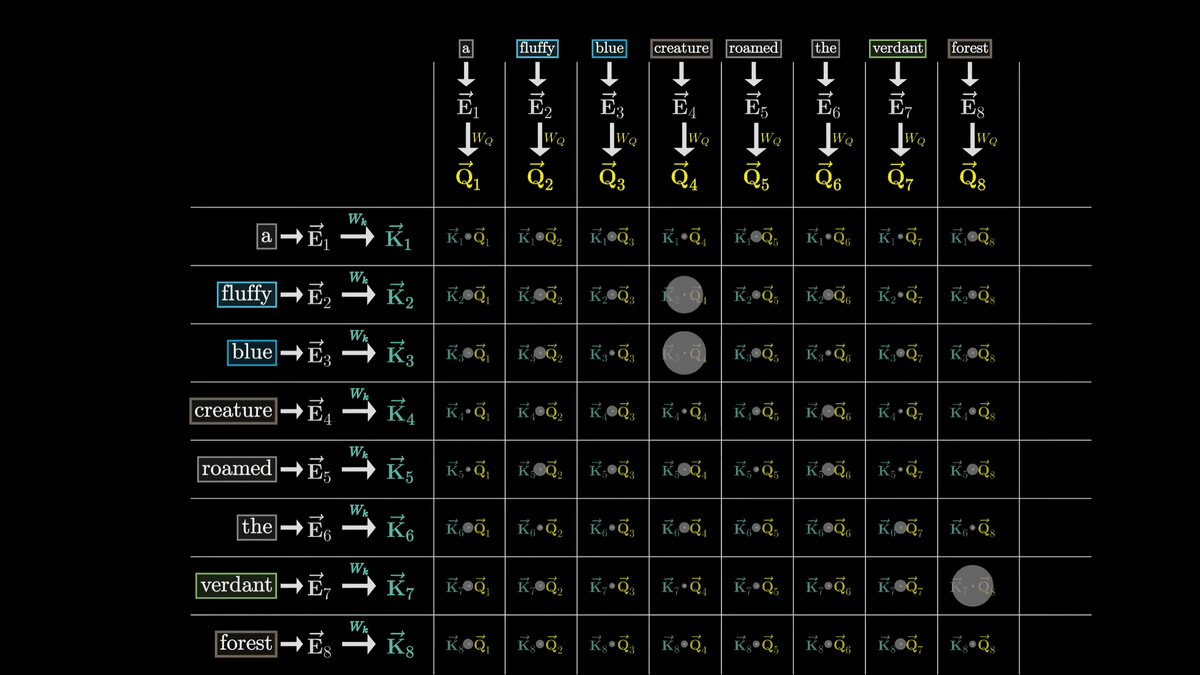
This shows that the embedded adjectives 'fluffy' and 'blue' are closely related to the noun 'creature.'

On the other hand, the dot product of the K vector of 'the' and the Q vector of 'creature,' which are completely unrelated, is very small.
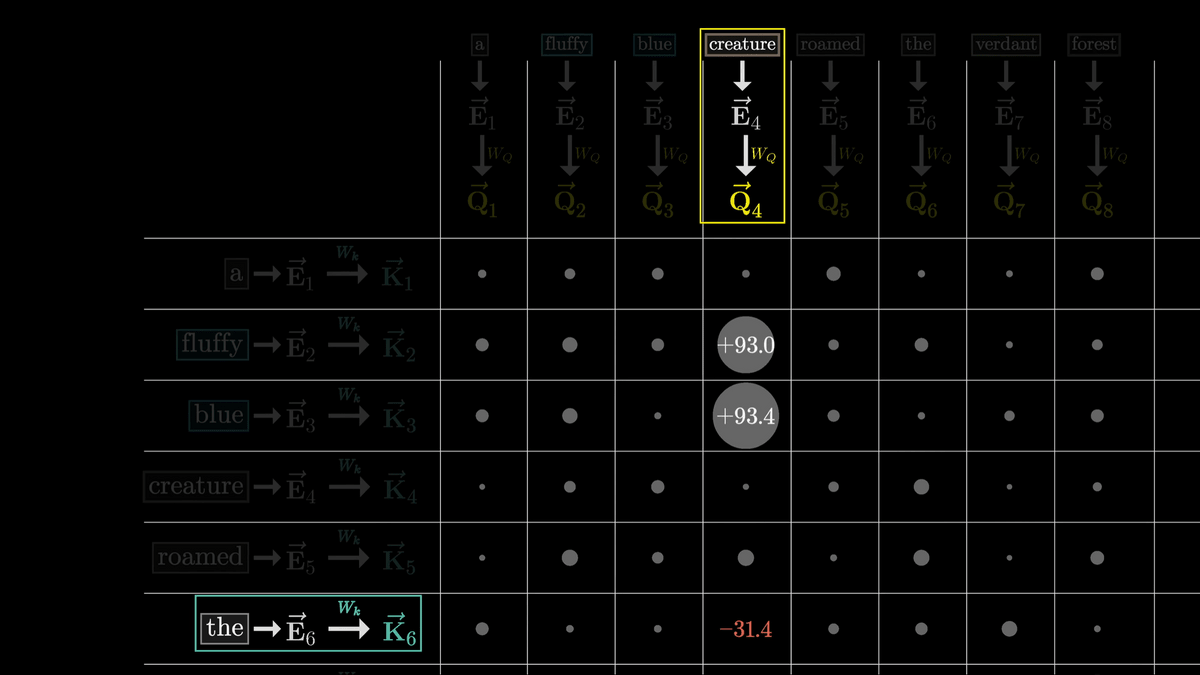
By calculating all the values in the grid, each box will be filled with numbers ranging from negative infinity to positive infinity.
However, to get the relative relevance of each word, we want to convert these to a weight-like form that sums to 1 rather than an arbitrary real number.
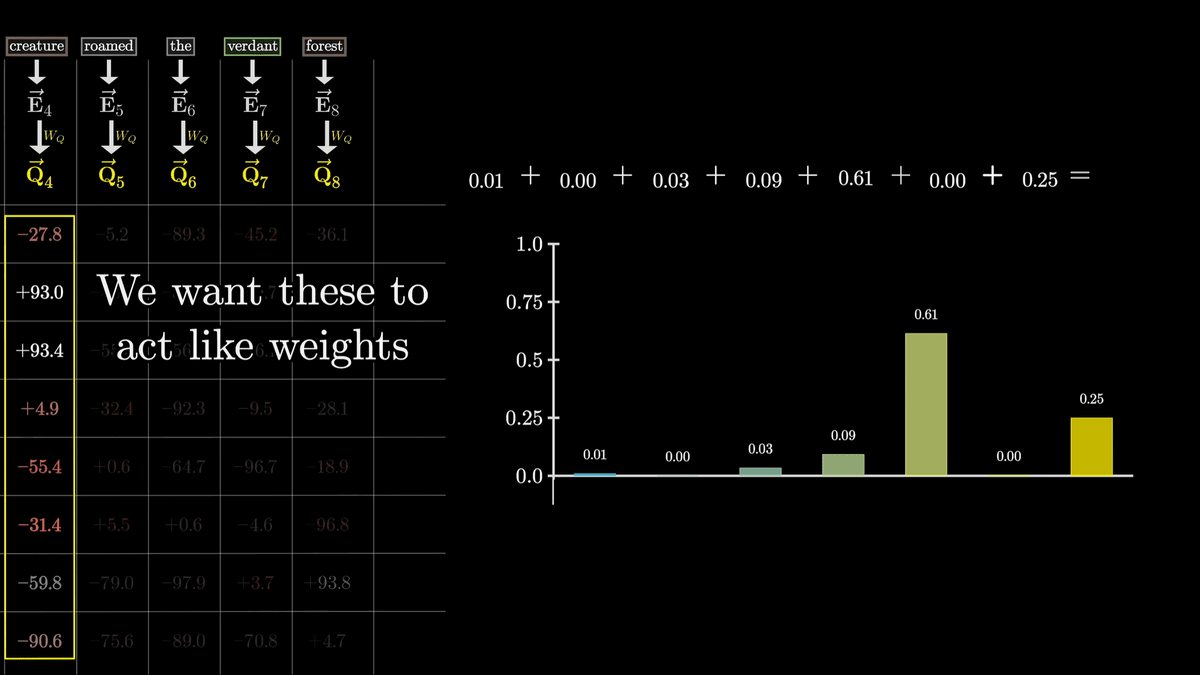
So we normalize it using
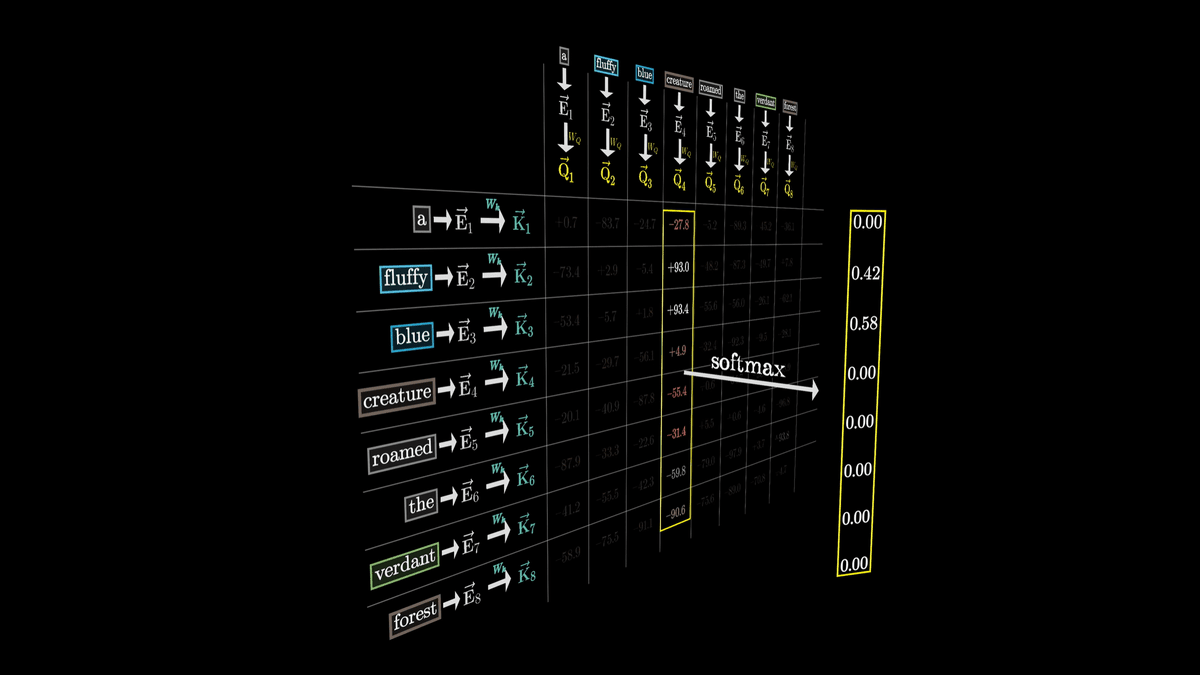
After normalization, the values are as shown below.
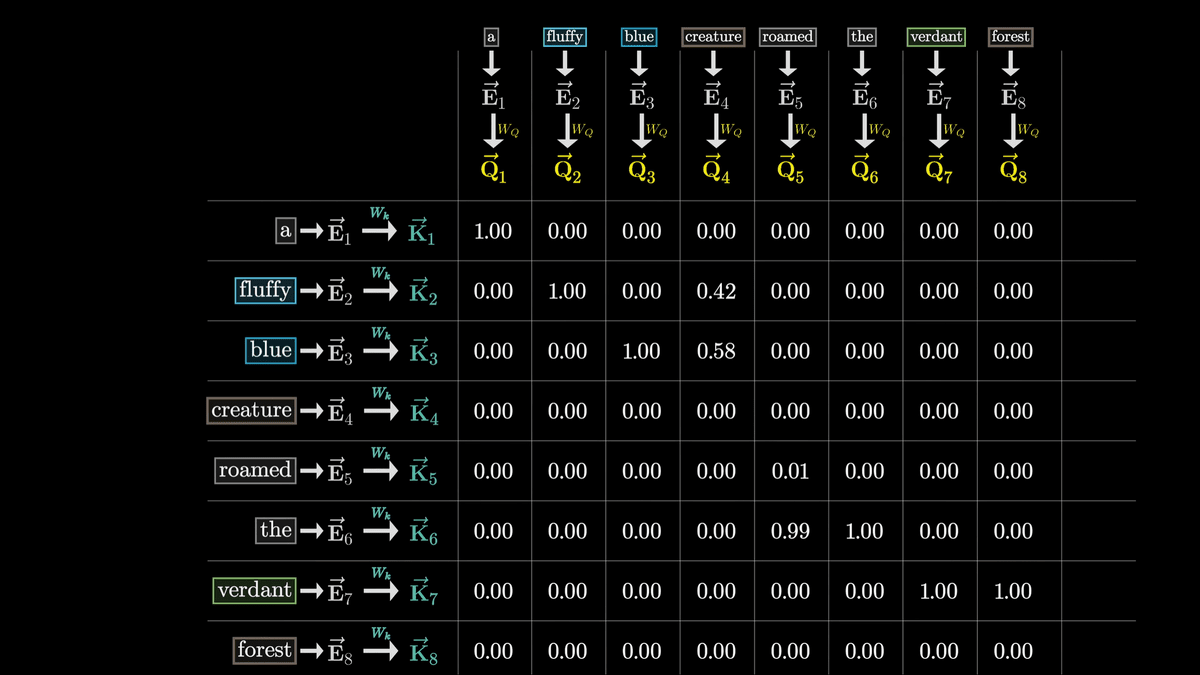
This grid is called the 'Attention Pattern.'
The attention paper, '

Q and K denote the arrangement of the Q and K vectors mentioned above.
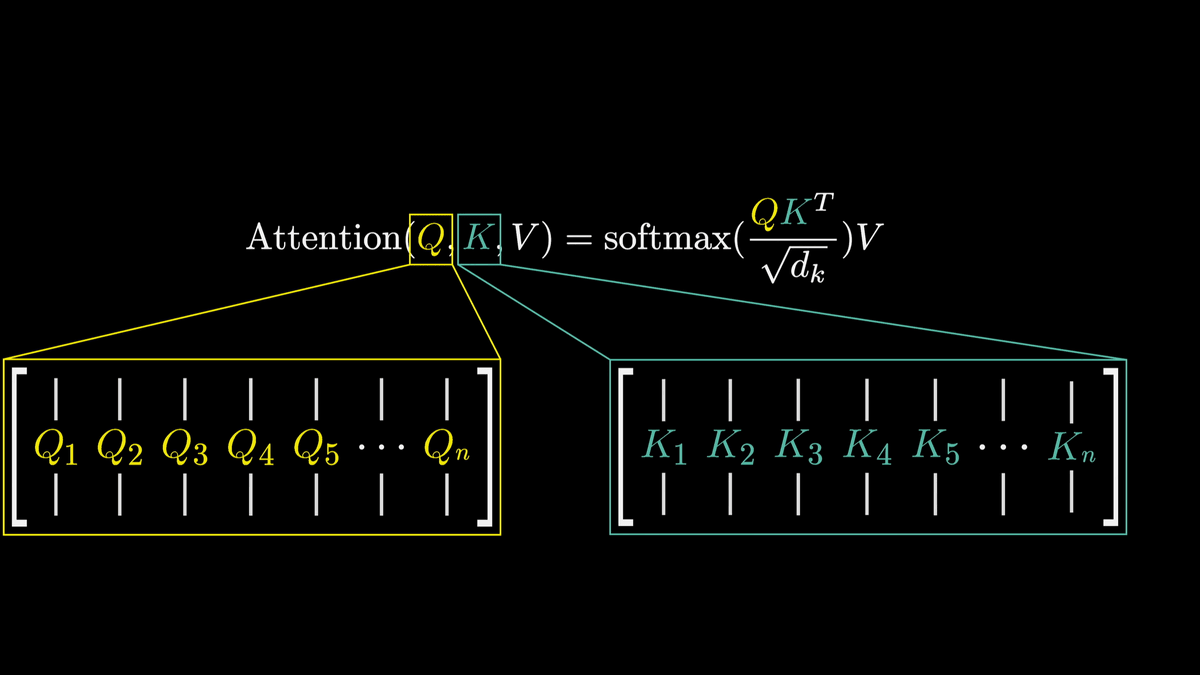
Therefore, 'QK^T' is the dot product of each Q vector and K vector.

In addition, to make the calculations numerically stable, the results are divided by the square root of the number of dimensions.
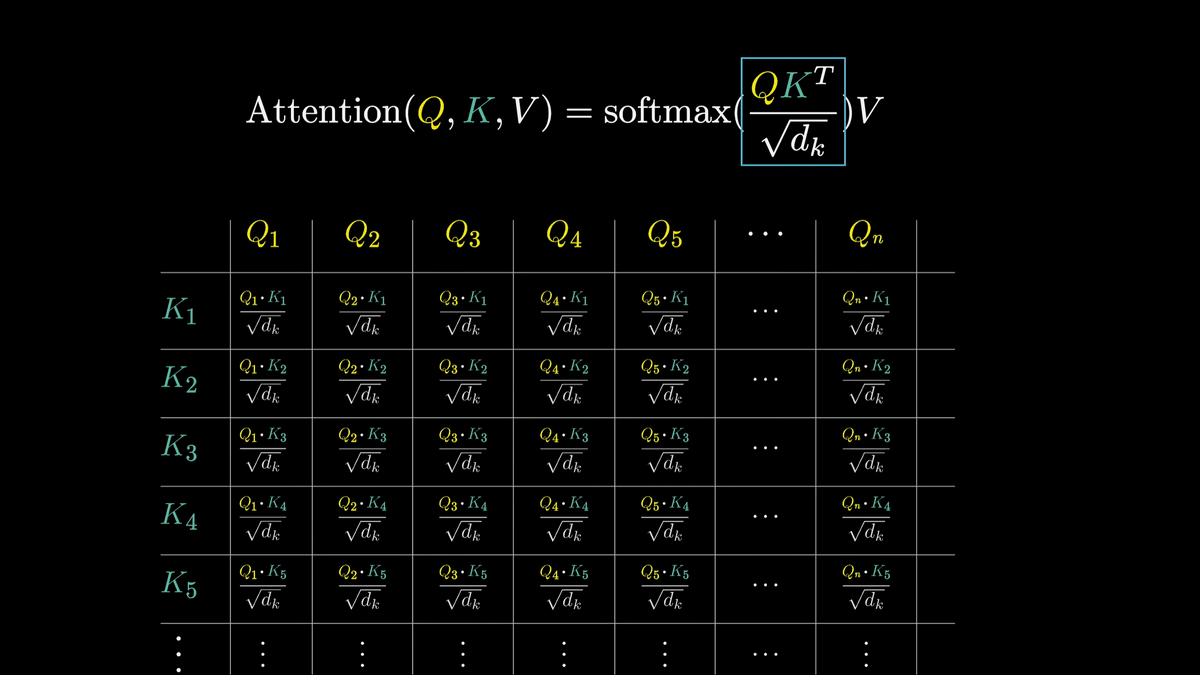
Then we apply softmax to normalize it.


In addition, 3Blue1Brown also has movies that explain things other than Transformer's attention , so if you're interested, please check them out.
Related Posts: